Overview: This chapter is arranged in four major sections. The first briefly reviews two simple contiguity models of classical conditioning (the models of Hull and Pavlov), and their problems. The second introduces the work of Rescorla. It presents his original contingency approach, what it was designed to handle, and why Rescorla abandoned it for the subsequent Rescorla-Wagner theory . The major successes of this latter, still influential theory are discussed, and its problems considered. The third discusses the Comparator Model Approach to classical conditioning. Two comparator models are briefly presented, along with their differences (in terms of processes and predictions) from the Rescorla-Wagner model. Finally, the fourth section briefly examines several memory-based models of conditioning. Mackintosh's Attentional Model is included here, but the emphasis in this section is on Wagner's Rehearsal Theory. Themes that will prove important in this section include the status of inhibition, and the adequacy of a behavioral-level approach that fails to include centralist, cognitive processes in accounting for learning.
The first assumption is the assumption of effective stimuli. So long as we have a CS or a UCS that is picked up by the animal's sensory system, classical conditioning will be possible. This assumption is meant to exclude failures of conditioning that are due to stimuli that simply do not register for an organism. Failure to condition a CS involving a certain sound wavelength in subjects incapable of hearing that wavelength is of no theoretical significance. (Notice, however, that we cannot use conditioning failure to decide that our CS or our UCS must have been an ineffective stimulus, because that would make the requirement of effective stimuli a completely circular claim that effective stimuli are whatever works. So, we need other procedures to convince ourselves that an animal notices or otherwise reacts to a stimulus. If we can show that, then we have an effective stimulus, and we ought therefore to be able to demonstrate classical conditioning with it.)
The second of these may be termed the assumption of independence of conditioned stimuli. According to this assumption, the formation of an association with one CS ought to be completely unaffected by any prior training with another CS, though as we saw in the last chapter, Pavlov did find that overshadowing occurred with the concurrent presence of other CSs. (Within reasonable limits, of course: a CS that is a blinding flash of light will certainly make another visual CS difficult to see. Cases such as these are excluded to some extent by the assumption of effective stimuli: The blinding light makes other visual stimuli ineffective.) In theory, then, an association may form between a UCS (or a UCR, in Hull's model), and numerous other stimuli.
The third assumption, of course, is the assumption of temporal contiguity. All that is needed for an association to form is the presence of effective stimuli (CS and UCS) at about the same time. (This assumption sometimes explicitly specifies that spatial contiguity of some sort is also required. While you are reading this, someone somewhere in the world is whistling. You don't form that connection, of course. But then, whistling half way across the globe is not an effective stimulus, because that stimulus does not register on your sensory system. Spatial contiguity is thus implied by the requirement for effective stimuli.)
The fourth assumption is the assumption of continuity: An association has continuously varying levels of strength in between 0% (no association) and 100% (maximum association). Normally, the process of classical conditioning (in which there are several pairings of effective stimuli) results in increases in level on each additional trial until the maximum strength is achieved. Thus, acquiring an association may be regarded as a matter of degree.
Despite these similarities, there are also significant differences. There are, of courses, differences in what the CS is associated with. But more significantly, recall that Pavlov was a centralist who talked about the association forming in the brain. Hull was more of a peripheralist who talked about a link forming between stimulus and response. Both included a notion of inhibition in their systems, but the inhibition involved very different mechanisms located in very different places. For Hull, inhibition was associated with the making of a response. For Pavlov, in contrast, the CS center in the brain contained both an excitatory and an inhibitory mechanism. The inhibitory mechanism could become conditioned to 'turn off' or otherwise block the activation occurring as a result of the CS center being stimulated.
In addition to the Pavlovian and Hullian models, we can also identify a behavioral-level version of the Pavlovian model that appealed to later behaviorists who didn't want to speculate about the physiological operations of the brain. In that model, two stimuli were associated, much as a stimulus and a response might be connected. Thus, some behaviorists came to treat classical conditioning as S-S learning, as opposed to the more traditional S-R approach. Regardless of which approach (behavioral versus physiological) was followed, however, theorists who did not adopt a Hullian account of classical conditioning tended to talk about learning as the CS substituting for the UCS: stimulus substitution theory.
One more wrinkle:
Behaviorists in general (and Skinner, in particular) were not
too happy with the notion of inhibition. You can easily imagine
why. Inhibition as applied in extinction and discrimination
appears to involve an association between a physically present event
(the CS) and a non-present event (the UCS). As pointed out
earlier, that seems to violate temporal contiguity, although it can
also be taken to violate the assumption of an effective stimulus (what
is the stimulus in the case of the missing UCS?). Following an
influential critique by Skinner that claimed that many effects
supposedly due to inhibition could be accounted for in some other
manner, behaviorist theorists generally stopped talking about
inhibition. Within the context of classical conditioning, this meant an
attempt to explain various phenomena as being due to competition
of excitatory associations, an approach which has a modern-day
descendant (although ironically, one with a distinctively cognitive
flavor) in the comparator theories in Section III below.
Thus, the time was right
for a quite different approach.
A good introduction to
the notion of contingency may be found in the following quote by
Rescorla (1968, p. 1):
The notion of contingency differs from that of pairing in that it includes not only what events are paired but also what events are not paired. As used here, contingency refers to the relative probability of occurrence of US in the presence of CS as contrasted with its probability in the absence of CS. The contingency notion suggests that, in fact, conditioning only occurs when these probabilities differ.Thus, in this early approach, the probability of successful conditioning could be described in terms of a two-dimensional contingency space in which the dimensions corresponded to (1) the probability of the UCS following the CS (this probability varied from 0 to 1, of course), and (2) the probability of the UCS following absence of the CS (also varying from 0 to 1). (This contingency space represents a number of simplifying assumptions, but most particularly including the assumption that CS and UCS do appear on some occasions, though not necessarily together.) Let us term these two probabilities Probability 1 and Probability 2, respectively. This being the case, we may identify three hypothetical conditions. In the first condition (involving a positive contingency ), Probability 1 (that UCS follows CS) is greater than Probability 2. This is precisely the circumstance under which Rescorla claimed that an excitatory CR should occur. The reason is that the CS is a better signal or predictor of the UCS than absence of CS is. In the second condition (involving zero contingency), Probability 1 is equal to Probability 2. As you may gather from the quote above, no learning having to do with the CS should occur. The CS doesn't matter here, because you get the UCS at the same rates regardless of whether the CS is there or not (a very different prediction than is made by contiguity theory, to remind you). And finally, in the third condition (involving negative contingency ), in which Probability 1 is smaller than Probability 2, Rescorla sought an explanation for inhibitory conditioning; conditioning that would pass the summation and retardation tests. If excitatory conditioning is the process of preparing for an upcoming UCS, then inhibitory conditioning is the process of preparing for its absence. And in this condition, the CS does a better job of signaling the UCS's absence, since the UCS is present more often when the CS is not there.
The concept of contingency is important. Indeed, sometimes it is critical. Just how important it is may be seen from the hearings that were held to determine the cause of the Space Shuttle Challenger exploding. The explosion's cause was eventually tracked to a faulty seal or 0-ring that allowed leakage of explosive rocket fuel. The 0-ring had turned brittle on a fairly cool morning, so it no longer sealed properly. People had earlier concluded that 0-ring failure had little to do with cold temperatures. The reason was that a check of 0-ring problems in previous space shuttle flights showed no relationship with temperature: There were some failures both at high and at low temperatures. But this is like asking how often the UCS is there when the CS occurs. The UCS may be there 50% of the time, so that just looking at this figure seems to suggest the CS is uninformative. But if the UCS is never there when the CS is absent, then it becomes obvious that the CS does actually predict the UCS. And that is what happened in part with the 0-ring problem. No one had looked at temperatures when 0-rings didn't fail. If they had, it would suddenly have become clear that 0-rings generally did not fail in warm temperatures; they were much more likely to fail in cold temperatures (see, for example, Gleick, 1992, pp. 427-428). Contingency requires tracking two probabilities.
The notion of contingency seems to suggest to many students an active animal doing some pretty high level thinking. But in fact, such need not be a requirement of this approach. Among humans, for example, there is evidence that we are extraordinarily sensitive to situational frequency (how often some event occurred in a given context). According to Hasher and Zacks, such sensitivity may be automatic, requiring relatively little attention or high-level cognition on our part. An animal sensitive to frequency information (including co-occurrence frequency) may thus have a built-in mechanism informing it about contingency.
Regardless of what process underlies the acquisition of contingency information, however, Rescorla gave up a strictly contingent approach in 1972. There were a number of reasons for this. Second-order (or higher) conditioning, for example, ought to be inhibitory (instead of excitatory) on this account, since CS2 is never paired with the UCS. Also, many studies exist showing effects of temporal contiguity in addition to contingency. A study we mentioned in the last chapter by McAllister, for example, showed steadily worsening conditioning with increasing CS-UCS delays in the human eyeblink paradigm. And as is suggested by Hinson and Siegle's study involving 10 sec intervals resulting in inhibition, there is a complex interaction possible between contingency and contiguity. At what point is the interval so long that the UCS is signaled more by absence of the CS?
Also, as we have seen, there is occasionally one-trial learning. The problem one-trial learning poses is that a contingency cannot have yet been formed, since the contingency requires tracking the relative probabilities of the UCS when the CS is there and when the CS is not! Moreover, how many trials are required for the animal to acquire a contingency? This approach suggests having first to collect a fair amount of data, so that it would seem to significantly delay learning.
In short, it became clear
that contingency by itself would not work. But the notion of
predictability that lay behind the original insight into contingency
was important, and
it was firmly implanted in a neo-contiguity model Rescorla developed
with
Wagner. The model included a contingency-like mechanism for calculating
what
should happen when a stimulus appeared without a UCS, although in this
later
model, that mechanism depended in turn on processing contiguity of a
sort.
It was the Rescorla-Wagner Model.
Second, in contrast to previous definitions that focused on what type of response was being acquired through which type of procedure (S-S or S-R pairing), Rescorla's definition focuses on "the underlying learning from which that response stems " (1978, p. 16, italics added). This embraces the learning-performance distinction : Performance (the behavior of the animal) presumably depends on learning, but is not the same as learning. Thus, we implicitly require a mechanism by which the animal's motives along with its knowledge combine to create a response. In this sense, unlike in the other, older definitions of classical conditioning, learning is not the acquisition of a new trigger for some old response. It involves knowledge from which an appropriate response might be selected (similar to Tolman's claims regarding instrumental conditioning: see the next several chapters). So, any change following classical conditioning may be taken as evidence of success. (When we discuss theories of operant and instrumental conditioning in a later chapter, you will see that Hull also makes a learning-performance distinction. His distinction, however, has to do with whether there is enough activation to trigger the response, and not with what response the animal may choose to emit.)
Third, if the animal is learning about the relations between events, it is also learning about the events themselves. Thus, specific characteristics or qualities of those events should be capable of influencing behavior. Such a claim can account for the results of devaluation studies such as Holland and Rescorla , or for the fact that different CSs paired with the same UCS sometimes result in different CRs (as in Holland).
It is important that you be aware of these points because, in discussing the Rescorla-Wagner model, we will be making some simplifications that are not readily consistent with these. In particular, we will temporarily ignore the learning-performance distinction, and use performance as our indirect measure of learning. So, below, when we ask how strongly a CS has conditioned, we will answer this question loosely by speaking of how strong the conditioned response has become. That, of course, assumes that we know what a good conditioned response is to track in a given conditioning situation, and that we have set up the situation so that our animal is motivated to perform in appropriate fashion.
In addition to surprisingness, however, there is the issue of the informativeness of the CS. Put briefly, informativeness refers to the extent to which the CS acts as a good signal or predictor for a UCS. Informativeness itself comprises several different features. One of these is relative signal value: If there are several CSs present, is one more likely to be selected than another? We have briefly come across this issue in discussing blocking: A CS that is perfectly redundant with another already-attended CS will not be likely to condition. In thinking about signal value, you should wonder about contextual cues, which are generally present when the UCS occurs. What makes a CS a better signal that the background context? A second characteristic of informativeness encompasses the notion of contingency: Is the UCS more likely when the CS is there, or when it is absent?
In any case, with this as background, the Rescorla-Wagner model was presented in terms of a mathematical formula that represented a claim about how surprisingness and CS informativeness would predict the formation of an association. That formula appears below (in slightly different form than was given in their paper, though):
![]()
In this formula, we designate an individual CS and an individual UCS by the subscripts i and j, respectively. The symbol V can be taken to represent the strength of an association (which also means that, in practice, we will allow it to represent the strength of a conditioned response). This strength may be positive (indicating excitation), negative (indicating inhibition), or zero (indicating no association). Thus, Vi is the strength of the association between CSi and UCSj, or -- loosely speaking -- the strength of its conditioned response. The triangle symbol (the delta) in front of the Vi is a mathematical symbol that means "change in." So, what this formula will attempt to do is inform us about how much change there will be in the conditioned response (or association) on any given trial. For that reason, it is sometimes referred to as the delta rule.
What about the V PresentCues? As we have seen from compound conditioning (and in particular, from our discussion of overshadowing), several CSs may sometimes be present on a given trial. Thus, there may be several CSs predicting the UCS on that trial. The VPresentCues is the extent to which all the cues present on a given trial are already predicting the UCS! So, in measuring a change in association on a trial, we will need to know how surprising the UCS is. If it is adequately predicted, then it won't be surprising at all, and no learning should occur.
An important point here: In compound conditioning where several cues or CSs are present, we are actually conditioning multiple CRs! The formula will have to be used separately for each present CS to determine what its CR will be. As a simplifying assumption, the overall reaction to the compound cues will be the sum of their individual conditioned responses.
How do we know whether the UCS is adequately predicted? Presumably, each UCS has a potential for causing a certain amount of learning that is closely related to its biological importance or significance. More important events have higher potentials, and may thus support higher levels of processing. So long as the UCS is being processed, additional learning will occur. A UCS's maximum potential is given by lambdaj in the formula above. This value may vary from 0 to the maximum potential. The value will be 0 during extinction trials , when an expected UCS is not there. Its maximum potential will depend on the individual UCS, of course, but will be very closely connected with UCS intensity: Higher levels of UCS intensity should result in higher maximum potentials.
We can speak of the maximum potential as the maximum association a UCS can form with a given CS. When that level is reached, the UCS is no longer surprising. In terms of the concepts we have introduced, the maximum level in simple conditioning may be regarded as identical to the asymptote of a learning curve (see the previous chapter), and the degree to which a UCS is surprising (and thus processed, causing additional learning) will be equal to the maximum level minus the extent to which the UCS is already predicted. Or in other words, the quantity below represents the surprisingness of the UCS:
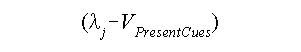
Notice that when that quantity is equal to 0, there will be no learning. When the quantity is positive, there will be excitatory learning: The conditioned response should become stronger. But note also that it is theoretically possible that the quantity will be below 0. In this latter event, a conditioned response should decrease in strength and, in some interesting circumstances, may actually become negative, resulting in inhibitory learning.
The final values in the formula, alphai and betaj , refer to the noticeability of the CS and the UCS respectively (normally, their intensity, although we have seen that for a CS the important issue is how big a change from background levels it represents). These are referred to as rate parameters: They determine the rate at which asymptote is approached, and therefore determine the speed of learning. These values will always be positive for effective stimuli (the values are at 0 for non-effective stimuli, and any 0 value in the formula will result in no learning occurring). The higher these values are, the bigger the change you will see on any given conditioning trial. The alpha parameter has the same subscript letter as the delta-V, to indicate that we have to use the rate parameter for the specific CS whose change we want to track; and for a similar reason, the beta parameter has the same subscript as the lamda. The VPresentCues has a different subscript because it is dependent on all the CSs present on that trial!
Below, when we look at some of the predictions the model makes, we will use a simplifying (and wrong) assumption that betaj is equal to 1, so that all we need to talk about is the salience of each of the CSs appearing in an experiment, and the asymptotic level of association of the UCS. That is, our calculations will be based on the following formula:
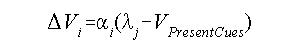
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | |||
| Trial 2 | |||
| Trial 3 | |||
| Trial 4 | |||
| Trial 5 | |||
On the left-hand part of the work sheet, we will track the strengths of the CRs for each of the CSs that appear on the current trial we are working with (Trial 1, Trial 2, Trial 3, etc.). In the middle, we will sum those CRs to obtain our Total V. As a quick approximation, the value for VpresentCues in the delta rule may be obtained by summing the separate CRs, and that will be the value for the middle column. You may then plug this value in the formula as the value for VpresentCues to obtain the results, which we will put in the columns on the right-hand part of the table. In those columns, we will have two values in each row for each conditioned stimulus: The value at the top of the row will be the figure we obtain from the formula, the change in CR strength. We will add that figure to the value directly above it to obtain what the new CR strength now is, and we will place that value at the bottom. That is why there are zeros in the very first row for our three CSs. We are assuming no conditioning, so their strengths are initially set to 0. When we add the changes, we obtain the new strengths. Hence, this table will allow you to track the newly forming associations using the following very simple rule:
new CRi strength = previous CR i strength + change in CRi strength
Let's start with a very simple example. We will assume a UCS with a maximum or asymptotic level of association being set to 100, and with the salience of the CSA being set to .5. (Salience, by the way, can never be over 1. In some sense, salience is how much attention the animal pays to a given stimulus or set of stimuli; it can't pay more than 100% of its attention!)
In our first trial, when there has been no previous learning, the formula will give us the following change for our CS:
change in CSA on Trial 1 = .5 ( 100 - 0) = 50
Note that VpresentCues is set to 0 in the
formula above, because there has been no previous conditioning with
this CS,
so nothing is predicting the UCS on this trial. Hence, the change
is equal to 50, and when we add that to the previous strength of this
CS (which
was 0), we get a new strength of 50 (indicated in bold type).
That
is how strong our conditioned response ought now to be. Filling in the
table
for this trial, we would put in the following figures:
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 | 0 | + 50 = 50 |
| Trial 2 | |||
I won't always do this on
the other examples below, but I have added in a plus sign and
an equals sign so that you can see that under the column on the
right labeled CSA, I am adding the change (50) to the
previous strength listed right above it (0) in order to get the new
strength. And now, before we go on to Trial 2, we can already fill in
one more part of the table,
since we know Trial 2 will involve pairing the UCS with CSA.
So,
doing this, the table will now show the following:
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 | 0 | + 50 = 50 |
| Trial 2 | 50 | 50 | |
change in CSA on Trial 2 = .5 ( 100 - 50) = .5 (50) = 25
And filling in the table for this trial and preparing it for Trial 3
gives us the following:
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 | 0 | + 50 = 50 |
| Trial 2 | 50 | 50 | + 25 = 75 |
| Trial 3 | 75 | 75 | |
If you look at the strength of CRA, it is the old strength (50: the last bolded value in the appropriate column on Trial 1) plus the change you have calculated on Trial 2 (25), and that gives you 75 (the bolded value on Trial 2). I have also placed this 75 in the CSA column on the left-hand side of the table (under VpresentCues) because this is the extent to which the UCS will be predicted by that CS on Trial 3. I have also put it in the middle column (under Total V) because that is the extent to which all CSs present on Trial 3 are predicting the UCS. (Since there are no other CSs involved at this point, that is not a terribly interesting situation. But I do want to get you used to thinking that you need to sum values on the left-hand side to get a middle value that will then be plugged into the formula).
Let's now go through the calculations for the next three trials:
change in CSA on Trial 3 = .5 ( 100 - 75) = .5
(25) = 12.5
change in CSA on Trial 4 = .5 ( 100 - 87.5) = .5
(12.5) = 6.25
change in CSA on Trial 5 = .5 ( 100 - 93.75) =
.5
(6.25) = 3.125
The table values (and you should verify this for yourself!) will
then be:
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 | 0 | + 50 = 50 |
| Trial 2 | 50 | 50 | + 25 = 75 |
| Trial 3 | 75 | 75 | + 12.5 = 87.5 |
| Trial 4 | 87.5 | 87.5 | + 6.25 = 93.75 |
| Trial 5 | 93.75 | 93.75 | + 3.125 = 96.875 |
And at the end of the fifth trial, as you can see from the table, we have a CR that is at 96.875. This is indeed very close to asymptote.
If you were paying close
attention, then you should have noticed that on each trial we
conditioned half of the remaining association. That is because
we had a rate parameter that was set to 50%. As you may gather from
this, if our rate
parameter would have been set to 10%, then on each trial we would have
conditioned only 10% of the remaining association. In that case,
although the asymptote would have remained the same, the conditioned
response would have been much weaker after Trial 5, simply
because we would still be so far away from asymptote. So, taking a
second group of animals with no prior conditioning and using a CS with
a salience of .10, we should obtain the following table (again, be sure
to calculate the values for yourself to check that you understand how
to use the formula and the table):
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 | 0 | + 10 = 10 |
| Trial 2 | 10 | 10 | + 9 = 19 |
| Trial 3 | 19 | 19 | + 8.1 = 27.1 |
| Trial 4 | 27.1 | 27.1 | + 7.29 = 34.39 |
| Trial 5 | 34.39 | 34.39 | + 6.561 = 40.951 |
You can see that the associative strength in this latter example is less than half way to asymptote.
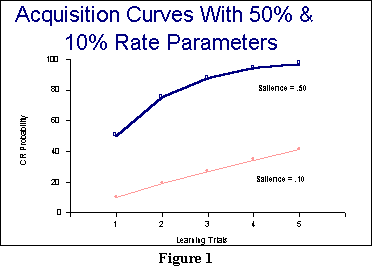 Figure 1 graphs the two
learning curves for these examples. Although it is not perfectly
obvious from the figure,
both lines will end at the same asymptote. The data that are plotted in
this
figure, of course, are the CR strengths that appear as the bottom
bolded
values in the CSA column on the right-hand side of the
worksheet.
So, in terms of the first few successful predictions, we can point out
that
the model predicts the correct general shape of a learning curve
(that is, diminishing returns). Moreover, it also successfully predicts
the CS salience effect: More salient CSs will generally exhibit
stronger conditioned responses then less salient CSs after the same
number of CS-UCS pairings. Any model that attempts to handle classical
conditioning findings will have to predict these effects at the least.
Figure 1 graphs the two
learning curves for these examples. Although it is not perfectly
obvious from the figure,
both lines will end at the same asymptote. The data that are plotted in
this
figure, of course, are the CR strengths that appear as the bottom
bolded
values in the CSA column on the right-hand side of the
worksheet.
So, in terms of the first few successful predictions, we can point out
that
the model predicts the correct general shape of a learning curve
(that is, diminishing returns). Moreover, it also successfully predicts
the CS salience effect: More salient CSs will generally exhibit
stronger conditioned responses then less salient CSs after the same
number of CS-UCS pairings. Any model that attempts to handle classical
conditioning findings will have to predict these effects at the least.
Another prediction that every aspiring theory must handle involves extinction. In extinction, the CR appears to decrease. Let's see how the Rescorla-Wagner model handles extinction. There may be a surprise here, given what you already know. Thus, we will assume a CR that is at an asymptote of 100, and that has a salience of .5 (as in our first example, except that conditioning has now been completed). When we start presenting that CS without the UCS, the lambda of the UCS is set to 0. The calculations over five trials thus become:
change in CSA on Trial 1 = .5 ( 0 - 100) = -50
change in CSA on Trial 2 = .5 ( 0 - 50) = .5
(-50)
= -25
change in CSA on Trial 3 = .5 ( 0 - 25) = .5
(-25)
= -12.5
change in CSA on Trial 4 = .5 ( 0 - 12.5) = .5
(-12.5) = -6.25
change in CSA on Trial 5 = .5 ( 0 - 6.25) = .5
(-6.25) = -3.125
The table values (and you should verify this for yourself!) will
then be:
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 100 CS B:0 CSc: 0 |
|
| Trial 1 | 100 | 100 | - 50 = 50 |
| Trial 2 | 50 | 50 | - 25 = 25 |
| Trial 3 | 25 | 25 | - 12.5 = 12.5 |
| Trial 4 | 12.5 | 12.5 | - 6.25 = 6.25 |
| Trial 5 | 6.25 | 6.25 | - 3.125 = 3.125 |
You should note that in the top row on the left-hand side of the table, we start out with a value of 100 for VpresentCues, since there has been some previous learning. By the end of the fifth trial, we have a CR that has very nearly disappeared. In fact, the asymptote in this case will be 0, so when the CS strength (or the CR) reaches 0, further learning will stop.
And that is the surprise. Pavlov insisted that extinction involved inhibition, but we don't see that in the Rescorla-Wagner formula. Instead, negative changes eat away at the former excitation until we are back to a 0 level. Consistent with this, Recorla's 1969 article reported that the CS after extinction failed to pass the summation and retardation tests!
Note too that in the Rescorla-Wagner model, extinction is exactly opposite to acquisition. The fact that we obtain negative changes on our extinction trials means that inhibition is building up. In this case, it continues to do so until the inhibition totally cancels out the excitation. But the conditioned response itself is never inhibited: That response never goes below zero, which is what we would need in order to obtain a CR capable of passing the summation and retardation tests. This is a very different view than is found in Pavlov, not only in terms of what is supposed to be happening in extinction, but also in terms of whether the same stimulus can have both inhibition and excitation attached to it, as Pavlov thought. The Rescorla-Wagner model does not allow both to occur as separate processes.
We have so far looked at simple conditioning; let us now look at compound conditioning. In the next example, we will take two CSs, at saliences of .2 and .3, respectively, and pair them with a UCS whose maximum or asymptotic level is 100. As you work through this example, compare the results to the chart for the first example we worked through (Table 2d).
Now, one point is important to keep in mind when we speak of compound conditioning: The two CSs are there at the same time, so it is impossible to tell which ought to condition first! Specifically, since both are present, we can think of them as engaging in a tug-of-war to capture whatever remaining association the UCS might have. Or to put this slightly differently, both condition at the exact same time . And that means that each will have exactly the same V presentCues . Thus, if CSA has a salience of .2 and CSB has a salience of .3, then our first trial will involve calculating the following values:
change in CSA on Trial 1 = .2 ( 100 - 0) = 20
change in CSB on Trial 1 = .3 (10 0 - 0) = 30
Let me stress again that on
any trial, all CSs conditioned on that trial will use the same value
for VpresentCues in their calculations! It is
very easy to assume that you have to include the change for the first
CS before
calculating the second (an error I see students doing all the time on
exams),
but you don't: The two CSs condition at the same time, so that is the
reason
why I have the same value (100-0, in this case) for how surprising the
UCS
is. Filling in the worksheet, we can add these values and prepare for
Trial
2 (where they will both be present) as follows:
|
|
|||
|
CSA: CS B: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 0 | 0 | + 20
+ 30 = 20 = 30 |
| Trial 2 | 20 30 | 50 | |
There are now some differences, if you compare this to Table 2b. We have moved the bolded CRs we obtained in Trial 1 to the appropriate columns under VpresentCues in Trial 2, and we have summed these to get the Total V, which we have placed in the middle column of the worksheet. This total will be the value we use for the next round of calculations.
Here are the calculations for Trial 2:
change in CSA on Trial 2 = .2 ( 100 - 50) = .2
(50) = 10
change in CSB on Trial 2 = .3 ( 100 - 50) = .3
(50) = 15
There is another common trap a number of students fall into at this
point: Instead of putting in Total V (50) in the formula, they
use just the strengths for each individual CS. So, for the first, they
subtract 20 from 100 to get 80 and then multiply this by 20%, and for
the second, they subtract 30 from 100 to get 70 and multiply the 70 by
30%. Remember: The surprisingness of the UCS depends on how much all
of the present cues are predicting it; you need to enter the total!
Adding these values to the worksheet and preparing for Trial 3 gives
us:
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 0 | 0 | + 20
+ 30 = 20 = 30 |
| Trial 2 | 20 30 | 50 | + 10
+ 15 = 30 = 45 |
| Trial 3 | 30 45 | 75 | |
change in CSA on Trial 4 = .2 ( 100 - 87.5) =
.2 (12.5) = 2.5
change in CSB on Trial 4 = .3 (10 0 - 87.5) = .3
(12.5) = 3.75
change in CSA on Trial 5 = .2 ( 100 - 93.75) =
.2
(6.25) = 1.25
change in CSB on Trial 5 = .3 (10 0 - 93.75) =
.3
(6.25) = 1.875
And the completed
worksheet:
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 0 | 0 | + 20
+ 30 = 20 = 30 |
| Trial 2 | 20 30 | 50 | + 10
+ 15 = 30 = 45 |
| Trial 3 | 30 45 | 75 | + 5
+ 7.5 = 35 = 52.5 |
| Trial 4 | 35 52.5 | 87.5 | + 2.5
+ 3.75 = 37.5 = 56.25 |
| Trial 5 | 37.5 56.25 | 93.75 | + 1.25
+ 1.875 = 38.75 = 58.125 |
As this example illustrates, the Rescorla-Wagner model can handle compound conditioning, including the finding that the more salient CS will capture more of the association (one of the features of overshadowing). As salience is in part bound up with signal value, this model captures that aspect of signal value.
But let's look at other
characteristics of overshadowing. To do so, we will run an experiment
involving five trials using a CSA with a salience set to .5
and a CS B whose salience has been set to .1. We will again
use a value of
100 for the UCS's lambda. (This is an arbitrary value, by the way. Some
students sometimes think that lambda is always 100; that is not so.
Lambda depends on UCS intensity, so we can make it 250, 36, or whatever
value we want. I am using 100 in this example to make the calculations
a bit easier.) I won't provide the calculations here (you should
attempt them yourself!), but here is the resulting worksheet for this
example:
|
|
|||
|
CSA: CS B: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 0 | 0 | + 50
+ 10 = 50 = 10 |
| Trial 2 | 50 10 | 60 | + 20
+ 4 = 70 = 14 |
| Trial 3 | 70 14 | 84 | + 8
+ 1.6 = 78 = 15.6 |
| Trial 4 | 78 15.6 | 93.6 | + 3.2
+ 0.64 = 81.2 = 16.24 |
| Trial 5 | 81.2 16.24 | 97.44 | + 1.28
+ 0.256 = 82.48 = 16.496 |
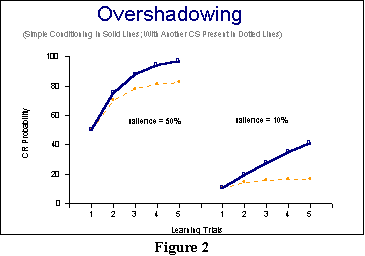 This comparison also appears
in Figure 2 (although I do want you to compare the actual
values in
the tables!). In this figure, the left-hand panel shows the
high-salience
CS both when it is presented by itself (the thick blue line with the
squares, if you have a color monitor), and when it is presented
compounded with a weaker
CS (in this case, its strength is tracked through the dotted orange
line
with the circles). Even though it is the stronger CS, in this case it
has
a weaker CR than when presented on its own. The reason, of course, is
that
the weaker CS is stealing away some of the association so that on each
trial,
there is less to condition, and thus, less to add to the strength of
that
particular association. The same thing happens, of course, to the weak
CS's
conditioned response graphed on the right-hand panel. You can see that
there
is a bigger difference for the weaker CS presented by itself
and compounded
than there is for the stronger CS: The lines are further apart! And the
reason
for that is that the stronger CS on each trial is capturing more
of the remaining association, leaving correspondingly less and less
association
for our weak CS. Thus, consistent with empirical results, the
Rescorla-Wagner
model successfully predicts that presence of another CS will cause overshadowing
whereby the conditioned response is not as strong as when a CS is
presented
by itself. The model also predicts that the degree of
overshadowing
should depend on the relative strengths or saliences of the cues in the
compound
.
This comparison also appears
in Figure 2 (although I do want you to compare the actual
values in
the tables!). In this figure, the left-hand panel shows the
high-salience
CS both when it is presented by itself (the thick blue line with the
squares, if you have a color monitor), and when it is presented
compounded with a weaker
CS (in this case, its strength is tracked through the dotted orange
line
with the circles). Even though it is the stronger CS, in this case it
has
a weaker CR than when presented on its own. The reason, of course, is
that
the weaker CS is stealing away some of the association so that on each
trial,
there is less to condition, and thus, less to add to the strength of
that
particular association. The same thing happens, of course, to the weak
CS's
conditioned response graphed on the right-hand panel. You can see that
there
is a bigger difference for the weaker CS presented by itself
and compounded
than there is for the stronger CS: The lines are further apart! And the
reason
for that is that the stronger CS on each trial is capturing more
of the remaining association, leaving correspondingly less and less
association
for our weak CS. Thus, consistent with empirical results, the
Rescorla-Wagner
model successfully predicts that presence of another CS will cause overshadowing
whereby the conditioned response is not as strong as when a CS is
presented
by itself. The model also predicts that the degree of
overshadowing
should depend on the relative strengths or saliences of the cues in the
compound
.
There is also one more prediction that ought to be pointed out: The values or strengths for both CSs in the first trial of compound conditioning were exactly equal to the simple conditioning values: The lines in both the right-hand and left-hand panels of Figure 2 start at the same spot. Or put another way, overshadowing only starts on Trial 2. There is evidence consistent with this prediction, as well.
You will recall from our discussion of Kamin's work on blocking that blocking is possible when a very weak CS is paired with a very strong CS. You can see something of the sort in Figure 2, as the dotted line on the right (our weak CS when it is in a compound with a strong CS) is clearly never going to get very strong (in fact, if you go back to Table 6, you will see that we are very close to asymptote, so that very little new learning can occur). A more dramatic example of blocking occurs when one CS is presented several trials before another. To demonstrate this phenomenon, we will take two cues that have equal saliences (both at .3), and present the first, CSA, for 4 trials. On the fifth and sixth trial, we will present the compound (that is, CS A together with CSB). We will again take a UCS with a lambda of 100. The design of this experiment is as follows:
Trial CS paired with UCS
1
CSA
2
CSA
3
CSA
4
CSA
5
CSA & CSB
6
CSA & CSB
You should work out the
calculations for yourself to verify the numbers in the worksheet below
(I will round to the nearest tenth, by the way):
|
|
|||
|
CSA: CS B: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 | 0 | + 30 = 30 |
| Trial 2 | 30 | 30 | + 21 = 51 |
| Trial 3 | 51 | 51 | + 14.7 = 65.7 |
| Trial 4 | 65.7 | 65.7 | + 10.3 = 76 |
| Trial 5 | 76 0 | 76 | + 7.2
+ 7.2 = 83.2 = 7.2 |
| Trial 6 | 83.2 7.2 | 90.4 | + 2.9
+ 2.9 = 86.1 = 10.1 |
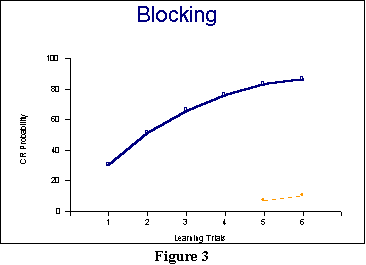 In this example (see also
Figure 3), even though our two CSs are equally salient, the first
captures the lion's share of the association. By the time the second is
presented, there is too little association left to enable conditioning
a strong response with it. And that is with only four prior trials
involving just CSA. If we had presented more trials, of
course, then the results for CSB would have been even more
dramatic. Still, if you look at Trials 5 and
6 in Figure 3 and compare the two CRs, the results are dramatic enough:
a much stronger conditioned response to the CS
presented
more often. The model thus correctly predicts blocking. In the
current
example, it is clearly sensitive to such issues as redundancy: A CS
presented
more often than another will have more opportunities to capture an
association. (Though there can be interesting interactions when the CS
presented less often is in fact significantly more
salient. In this case, our two signal value mechanisms may compete
against one another.)
In this example (see also
Figure 3), even though our two CSs are equally salient, the first
captures the lion's share of the association. By the time the second is
presented, there is too little association left to enable conditioning
a strong response with it. And that is with only four prior trials
involving just CSA. If we had presented more trials, of
course, then the results for CSB would have been even more
dramatic. Still, if you look at Trials 5 and
6 in Figure 3 and compare the two CRs, the results are dramatic enough:
a much stronger conditioned response to the CS
presented
more often. The model thus correctly predicts blocking. In the
current
example, it is clearly sensitive to such issues as redundancy: A CS
presented
more often than another will have more opportunities to capture an
association. (Though there can be interesting interactions when the CS
presented less often is in fact significantly more
salient. In this case, our two signal value mechanisms may compete
against one another.)
What about situations such as backwards conditioning or the explicitly unpaired procedure , in which we obtain inhibition (as verified through the summation and retardation tests)? To account for these, we need to add in one more idea. That is that contextual cues present when the UCS is there will also be weakly conditioned to yield an excitatory response (recall the study by Hinson and the control study by Balaz et al. mentioned in the previous chapter). So, when the UCS is absent but a new CS (say, salience of .5) is present, then VpresentCues will be positive due to the context predicting the UCS. Let us pick a weak value such as 20 for VpresentCues . In that case, the first few trials with our new CS (the one that should become inhibitory) will be as follows:
change in new CS on its 1st Trial = .5 ( 0 -
20) = .5 (-20) = -10
change in new CS on its 2nd Trial = .5 ( 0 -
10) = .5 (-10) = -5
So, as you can see, this stimulus is actually obtaining an increasingly negative value. The model has a mechanism for predicting inhibition in the proper circumstances. Namely, in a situation in which there is a negative contingency, slight residual excitation from the general context will result in VpresentCues being larger than lambda (0 when the UCS is absent), generating negative strengths.
There are a number of other successful predictions that may be generated from this model (see, for example, the review article by Miller, Barnet, & Grahame, 1995), but let's concentrate on just a few more that involve this notion of VpresentCues being greater than lambda. Obviously, one situation in which this occurs involves absence of the UCS, as in extinction or backwards conditioning. But that need not be the only circumstance in which it occurs. Suppose, instead, that we condition a CS with a salience of .5 (and a UCS with a lambda of 100) for three trials and then, on the fourth trial, reduce the intensity of the UCS from 100 to 77.5, according to the following experimental design:
Trial CS-UCS Pairings UCS Lambda
1
CSA &
UCS
100
2
CSA &
UCS
100
3
CSA &
UCS
100
4
CSA &
UCS
77.5
In this case, our calculations will be:
change in CSA on Trial 1 = .5 (100 - 0) = 50
change in CSA on Trial 2 = .5 ( 100 - 50) = .5
(50) = 25
change in CSA on Trial 3 = .5 ( 100 - 75) = .5
(25) = 12.5
change in CSA on Trial 4 = .5 (77.5 - 87.5) = .5
(-10) = -5
Note particularly what happens on Trial 4: The value for lambda is now the new value of 77.5 (rather than the old value of 100), and since this is less than the VpresentCues, a bit of inhibition starts building up, causing the conditioned response to decrease from 87.5 in Trial 3 to 82.5 in Trial 4. Reducing the lambda establishes a new asymptote, and learning will now be driven towards that new asymptote. Thus, if the amount of association that had been bound up until that change was over the amount in the new asymptote, additional learning will involve decreases in the strengths of the conditioned responses. That result has indeed been verified. Buildup of inhibition need not require an absent UCS!
Another demonstration of a similar result comes from a series of studies by Kremer. Kremer takes two CSs and pairs each singly with the UCS, until each is at or near asymptote. He then presents the CSs together in a compound. If you think about what should happen on this latter trial, you should conclude that inhibition will start building up. Let's take an example to demonstrate this. This time, we will use a maximum asymptotic value of 200, and two CSs that are each at a salience of .4. We will pair each 4 times with the UCS, and then present them together. So, to keep you straight, here is the design:
Trial CS paired with UCS
1
CSA
2
CSB
3
CSA
4
CSA
5
CSB
6
CSB
7
CSB
8
CSA
9
CSA & CSB
In this design, the two
CSs have been presented in a random order. For our purposes at the
moment, order will not prove important for discussing what happens.
Again, you would be wise to run through the calculations on your own;
assuming you have, they should match those presented in the following
worksheet (rounded to the nearest tenth):
|
|
|||
|
CSA: CSB: CSc: |
TOTAL V |
CSA: 0 CS B: 0 CSc: 0 |
|
| Trial 1 | 0 | 0 | + 80 = 80 |
| Trial 2 | 0 | 0 |
+ 80 = 80 |
| Trial 3 | 80 | 80 | + 48 = 128 |
| Trial 4 | 128 | 128 | + 28.8 = 156.8 |
| Trial 5 | 80 | 80 |
+ 48 = 128 |
| Trial 6 | 128 | 128 |
+ 28.8 = 156.8 |
| Trial 7 | 156.8 | 156.8 |
+ 17.3 = 174.1 |
| Trial 8 | 156.8 | 156.8 | + 17.3 = 174.1 |
| Trial 9 | 174.1 174.1 | 348.2 | - 59.3
- 59.3 = 114.8 = 114.8 |
Keeping track of the VpresentCues in the above worksheet may have been a bit difficult for you. As a guide, when I came to a given Trial, I first looked to see which CS was predicting on that trial. I then checked that CS's column on the right-hand side for the last entry, and moved that value into the VpresentCues column. So, for example, the design on Trial 8 called for CSA to be paired with the UCS. On the right-hand columns, the last value for this CS was 156.8 (calculated on Trial 4), and that was therefore the appropriate value to plug in (and to sum into the middle column).
One more prediction based on Kremer's work, and then we're done with this section. On the last trial of the previous experiment, instead of just presenting CSA and CSB, let us also add in a new, third CS (of equal salience) to be paired in a triple compound with the UCS. What should happen?
One of the strengths of mathematizing a model (particularly complex models) is that it can sometimes generate an unusual prediction. Based on what we've learned so far, a seemingly natural and commonsensical prediction would be that nothing should happen with the new CS: It is perfectly redundant with the other two CSs that are doing a good job of signaling the UCS. Alternatively, perhaps it might gain a bit of excitation by being paired with the UCS, assuming that blocking won't be perfect. But in fact, the delta rule predicts a radically different result. Let's go through the calculations for this new Trial 9 to see why:
change in CSA on Trial 9 = .4 (200 - 348.2) = -59.3
change in CSB on Trial 9 = .4 (200 - 348.2) = -59.3
change in CSC on Trial 9 = .4 (200 - 348.2) = -59.3
Not surprisingly, for our three equally salient CSs, there is the same identical change. But to see how strong the conditioned responses are, we need to add the change to the previous strength. And if we do that, we obtain the following:
CRA after Trial 9 = old strength (174.1) +
change
(-59.3) = 114.8
CRB
after Trial 9 = old strength (174.1) + change
(-59.3) = 114.8
CRC
after Trial 9 = old strength (0) + change (-59.3) = -59.3
So here is the surprise: The new CS should become inhibitory! And that is exactly what Kremer finds. The reason, of course, is the same one mentioned above: If all the predictors are summating to an amount different from and above asymptote, then there will be negative change for each predictor until the association has settled back down to asymptotic level. And that means that a new predictor will go into the negative values at the same time that old predictors weaken, but stay positive.
These are, all-in-all, a very impressive set of verified predictions. Based on them, you can see the appeal of a model that may be captured in a fairly simple formula. But as we will see in the next section, there are an equally impressive number of failures. Thus the model has been more successful than Pavlov's or Hull's models in terms of the number of findings it has accounted for, but it has not been successful enough.
A sample study of that later work involves a recent article by Rescorla. He trained rats to move a lever or pull a chain for different reinforcers (one of these responses was reinforced with a pellet of food, the other with a sip of sucrose). These two reinforcers then became UCSs in classical conditioning, with one UCS being paired with a light, and the other with a noise. These CSs ought to become conditioned excitors (much as CSs associated with an aversive UCS become conditioned suppressors), and indeed, Rescorla found that during later extinction of lever moving or chain pulling, the presence of a CS associated with the same outcome resulted in initially slower extinction. So, if a rat had learned to pull a chain for sucrose, presenting the CS associated with sucrose during chain pulling extinction caused more responding in the initial sessions of extinction, although by the end of extinction training, the same level of extinction was eventually reached by all groups. That so far ought not to surprise you: Both the chain and the CS have been associated with sucrose, so the sucrose is being signaled quite strongly at the start of extinction.
Following extinction, Rescorla retrained his animals on these responses, but used the opposite reinforcers: If chain pulling had been reinforced with sucrose, it was now reinforced with a pellet. The animals relearned these quite rapidly. The question Resorla sought to answer was, what would happen when one or the other of these CSs occurred while the animal was making one or other of these responses. Rescorla found that the CS that had caused more responding during extinction now acted as a conditioned suppressor causing less responding in the situation where the animal was making the same response. So, if the CS caused more responding of chain pulling during extinction, it depressed chain pulling during later performance, even though the chain pulling was now associated with a different reinforcer than signaled by the CS. Thus, there was evidence both that a CS could become inhibitory, and that this inhibition was specific to the relationship between the CS and a particular response. Rescorla (1997, p. 249) concludes that :
The precise associative structure of these inhibitory associations remains to be fully worked out. We have described them in terms of simple binary associations between S and R. But it is equally possible that they involve a more elaborate hierarchical structure in which S signals that R will be followed by no event.Are you surprised that the processes involved in extinction are still a hot topic in the late 90s? Finding a satisfactory explanation of what happens during extinction is still a pressing goal.
While on the topic of inhibition, note that the Rescorla-Wagner model claims inhibition ought to be the reciprocal of excitation. But, inhibition normally takes much longer to develop than excitation, and at least in some cases (compensatory responses, for example) appears to involve a process in addition to excitation, rather than a direct canceling out of the excitation (a view consistent with the results of Rescorla's more recent work above). Moreover, one occasionally sees excitatory CRs in conditions where inhibitory CRs should have been expected. Normally, these occur in situations in which a small number of conditioning trials have been given. Nevertheless, they fail to conform to the model. Why would a few trials of backwards conditioning, for example, result in excitation?
Besides extinction, the delta rule provides little or the wrong guidance on higher-order conditioning: If contiguity is used to establish the existence of a positive contingency, then why do we obtain results suggesting a positive contingency between the second CS and an absent UCS? This was a problem for the contingency approach, and it really wasn't solved by the Rescorla-Wagner model. That model, of course, did not explicitly deal with the relationship of stimulus similarity in a way that would account for the Rizley and Rescorla results (though it did deal with stimuli as consisting of component elements, so that generalization could be described in terms of number of common elements conditioned to the UCS). Similarly, it wasn't geared towards handling the belongingness effects in the learned taste aversions paradigm, nor the interactions of belongingness with temporal contiguity found by Krane and Wagner .
More seriously, the model failed to handle some compound conditioning results. Particularly prominent among these is potentiation, briefly described in the last chapter. The problem, of course, is that the model predicts overshadowing when two CSs are presented at the same time, but potentiation is actually the opposite: a weak CS becomes stronger in the presence of another, stronger CS. In addition, the model clearly predicts that overshadowing ought to occur starting with Trial 2. However, several studies report overshadowing with a single trial.
Another problem in the area of compound conditioning concerned the phenomenon of unblocking . The Rescorla-Wagner model could correctly predict some unblocking results, but not all. Thus, in Kamin's unblocking experiment (discussed in the previous chapter), a light compounded with a tone unblocked when the UCS shock increased. To remind you of Kamin's study, the relevant conditions were as follows:
Group Phase 1 Phase 2
blocking of
light
tone & 1 mA shock
light, tone & 1 mA shock
unblocking of light
tone
& 1 mA shock light,
tone
& 4 mA shock
This result is easy to explain, because the increase in shock means
that lambda has increased. Thus, while the tone has captured
most
of the association so far, the model would correctly predict some new
association being freed up that the tone and light could compete for.
And if the light is more salient than the tone (see the previous
discussion
of this experiment), then it will now capture a fair chunk of those new
resources. To see a mathematical illustration of this, let's assume
that we start off with a UCS whose lambda is 100. Let's further assume
that the tone has a salience
of .2, and the light has a salience of .4. Let's also assume that
increasing
the shock to 4 mA effectively increases lambda to 200, and that our
tone
had a CR of 84 by the end of Phase 1. In those conditions (and you
could
have easily chosen other values to illustrate the same point), our
first
two trials of compound conditioning (call them Trials 61 and 62) in the
unblocking
group should give us the following:
|
|
|||
|
|
TOTAL V |
tone: 84 light: 0 |
|
| Trial 61 | 84 0 | 84 | + 23.2
+ 46.4 =107.2 = 46.4 |
| Trial 62 | 107.2 46.4 | 153.6 | + 9.3
+ 18.6 =116.5 = 65 |
In contrast, Trials 61 and 62 for the blocking group would have
yielded:
|
|
|||
|
|
TOTAL V |
tone: 84 light: 0 |
|
| Trial 61 | 84 0 | 84 | + 3.2
+ 6.4
= 87.2 = 6.4 |
| Trial 62 | 87.2 6.4 | 93.6 | + 1.3
+ 2.6 = 88.5 = 9 |
The model thus correctly expects a much stronger CR for the new CS when UCS intensity increases in compound conditioning.
But how can this model account for the Dickinson, Hall, and Mackintosh experiment that involved the following setup (again, see Chapter 2 for more details):
Group Phase 1 Phase 2
light blocking click, 2
shocks 8 sec apart
light
& click, 2 shocks 8 sec apart
light unblocking click, 2 shocks 8 sec
apart light &
click, only 1 shock
The problem is that the unblocking condition involves what appears to be a reduction in lambda (one shock instead of two) which should result in an even smaller response to the click than in the blocking group. (As an exercise, you should try to play around with some figures to convince yourself that this is the case, even if the reduction now results in lambda being below VpresentCues!)
Most seriously, perhaps, a number of people at the time became convinced that the model's failure to handle changes in the processing of the CS was its Achilles' Heel. Among the CS findings that could not easily be handled by the model were latent inhibition, learned irrelevance, and the finding that CS intensity or salience can apparently influence not only rate of learning, but also where the final asymptote will be (something that ought to be influenced just by the UCS in the Rescorla-Wagner model). We have already talked about latent inhibition; learned irrelevance had to do with Rescorla's claim that truly random control was the proper control for learning, rather than the explicitly unpaired procedure. In the truly random control , the CS and UCS are paired at random to yield a zero contingency, precisely the condition that the model claims ought to result in no learning. But, Rescorla found that the CS in this condition (and in latent inhibition) retards later excitatory learning, although it fails to pass the summation effect. Whatever is going on, then, it does not appear to involve true inhibition.
There were other critiques and findings that did not fit, and you may wish to consult the Miller et al. review article for more examples and details. In addition, there have also been attempts to update the Rescorla-Wagner model in order to handle some of these problems (see, for example, Van Hamme & Wasserman, 1994).
In any case, Wagner and
his colleagues, in particular, developed a new generation of models to
add in a component of CS processing along with UCS processing (as did
other
theorists such as Hall and Pearce). We will examine Wagner's
model
shortly. But first, let us briefly look at an alternative class of
models
(the comparator models) that attempted to account for findings
in
terms primarily of excitatory links.
There are several different flavors of comparator models. We will concentrate on Miller's comparator hypothesis. The precursor to this model, however, was Gibbon and Balsam's scalar expectancy theory (SET: see also Kaplan). In each, UCS presence is always associated with something . To give you a taste in advance of how these models differ from the Rescorla-Wagner model, consider the following quote from Miller and Schachtman (1985, p. 52):
Associations involving negative associative strengths or CS-no US relationships are not assumed. Behavior indicative of what is ordinarily regarded as conditioned inhibition can be explained without recourse to theoretical constructs such as negative associations [or] associations to the absence of the UCS.As you read about these models, keep in mind studies supposedly involving inhibition and ask yourself how a comparator model might handle these.
So far, I have been presenting the theory under the assumption that at test, when we see whether we have a CR to our CS, the background context is identical to what it was during training. But SET also explicitly claimed that the comparison proportion would depend not on the exact context during training, but rather on the context at test. Thus, in theory, a CS which may exhibit no conditioned response in the same context could become capable of a strong conditioned response in a context that has not been associated with the UCS. This should remind you a bit of the studies involving dishabituation or disinhibition with switch to a new context.
How might such a theory account for extinction or discrimination? In extinction, the value of T starts changing, as does the value of C, since each is now becoming associated with longer waits. But those longer waits also cause the ratio to drop. Thus, to take an example, if our ratio is 6/2 , at some point in extinction training we might add the same amount (3) to both C and T. The ratio now becomes [6/3]/[2+3] or 9/5, which is now less than our critical value of 2. And of course, exactly comparable calculations can be performed for two CSs during discrimination training: The CS+ will have a much shorter T than the CS-, resulting in very different ratios for the two.
However, SET has not
fared too well. The evidence that responding depends on comparing current
test context with the CS does not support the claims of the theory.
In short, the evidence does not seem to fit the claim that when the
current
context does a good job of predicting the UCS, the responding to the CS
goes
down.
Another difference concerns the processes involved in comparison. Essentially, the UCS may be activated through a direct and an indirect route, and the comparison involves which one of these does the better job. The direct route, of course, consists of the link between the CS and the UCS, and depends on contiguity and how many times CS has been paired with UCS. In contrast, the indirect route involves the fact that the CS has also been paired with other cues such as (but not limited to) the background cues, and these, in turn, are linked to the UCS. Thus, presentation of a CS activates two routes: the direct route due to the CS-UCS link, and the indirect route by which CS activates background cues which activate UCS. As in SET, the relative activation of these is compared to determine relative rate of responding. If the background or comparator cues do a reasonably good job of accounting for the UCS, then we ought not to expect a conditioned response to the CS.
The following diagram may help make the direct and indirect routes clear:
CS ------------------------> UCSD ---------------->
|
Comparison
Comparator Cues -----------> UCSI ----------->
In this diagram, representing the simplest case, there are three associations represented by (1) the link from CS to UCSD (the subscript is used here to suggest direct activation of the UCS by the CS), (2) the link from CS to comparator cues, and (3) the link from comparator cues to UCS I (the subscript I represents indirect activation through the route involving the comparator cues). UCSD and UCS I are then input into an automatic, unconscious comparison process.
Where do the comparator cues come from? In this model, the comparator stimulus may be thought of as the most salient stimulus present in addition to the CS. One might normally think of these as representing the context, as in the case of simple conditioning, in which we try to draw the organism's attention to only one event (the CS). But where we have other stimuli due to compound conditioning, or due to prior training, then these may be regarded as compartor stimuli. A critical point here is that the strength of an association will reflect the relative saliences of the stimuli (see, for example, the recent review of the comparator hypothesis by Denniston, Savastano, and Miller, 2001). Thus, in compound conditioning in which one CS is more salient than another, the more salient one will form a stronger association with the UCS.
There is a second critical
point here: How to determine which is stronger, the direct route
or the indirect route. The direct route in the diagram above will
depend on the strength of the CS and of the UCS. But what about
the indirect route? This will depend on the strengths of the
other two associations (that between the comparator cues and the
CS, and that between the comparator cues and the UCS). The rule
here is that the strengths of these two
associations are combined multiplicatively. So, if one of
these associations is weak, then multiplying the weak association
against the other will still result in a weak association. On
this account, for example, blocking will work because prior
presentations of one CS have resulted in such a strong association with
the UCS that the later weaker associations cannot overcome it.
Thus, the associations are there, according to this
model, but apparently unobserved due to the stronger association with
the
first CS winning the comparison.
We have already met with at least one study in the previous chapter that was inspired by the comparator approach. To remind you, Balaz, Capra, Hartl, and Miller found that 'extinguishing' responses to a given context (by pre-exposing that context) resulted in greater expression of the CS. A similar result was obtained in a study by Matzel, Brown, and Miller. This result is consistent with two claims of the comparator model: First, it fits the claim that animals compare the CS with the comparator stimuli. If responding were based just on the CS, then contextual cues ought to be unimportant. Second, it fits the claim that the comparator stimuli are the stimuli present during training. Anything that weakens those comparator stimuli should result in a corresponding increase in responding to the CS, since the comparison will now increasingly favor the CS. And that is what both experiments found.
Of course, the hypothesis will also handle phenomena like extinction and discrimination in the same manner as SET.
However, the comparator hypothesis forces us to take a quite different perspective on a number of phenomena. It has been useful if for no other reason than that. Thus, it may surprise you to learn that the comparator hypothesis claims that normal learning (in terms of the formation of an association) occurs in both overshadowing and latent inhibition, as opposed to theories like Rescorla-Wagner (and the Attentional Theories in the next section) that claim a learning deficit at the heart of these effects. But people utilizing the comparator approach have come up with some very clever experiments in support of their claims that there is, instead, a response deficit . For example, in overshadowing, a strong CS (A) results in weakened responding to a weaker CS (X) with which it is compounded. You have seen in the Rescorla-Wagner model that Rescorla and Wagner's explanation for this involves more association being captured by the stronger CS. In the comparator hypothesis, on the other hand, the claim will be that X will have only a weak association with the UCS relative to the association of A with the UCS (which is activated by the association of X with A). An obvious prediction, then, is that we ought to be able to get a strong conditioned response to X by deliberately weakening A through extinction procedures. Matzel, Schachtman, and Miller have done this experiment, and indeed report an increase in the resulting conditioned response to X.
A similar logic will apply to latent inhibition, in which pre-exposing a CS results in a lessened conditioned response once the UCS is introduced. On this account, pre-exposure results in a very strong link between the CS and the background comparator stimuli. Both are subsequently conditioned to the UCS. But since presentation of the CS activates both the UCS and the comparator stimuli, and since both are near the same level, we have an unclear situation. If we can thus deliberately extinguish the background comparator stimuli, we ought to find that the comparison involving the CS strengthens, resulting in release from latent inhibition. That study was done by Grahame, Barnet, Gunther, and Miller, and the results were as predicted by the comparator hypothesis.
In case it wasn't obvious, in both of the above studies, extinction of comparator stimuli occurred after conditioning with the CS at issue. Thus, no additional training with the CS that might have increased its strength occurred. Rather, the studies allowed the CS-UCS association to win the comparison by weakening the comparator-UCS associations. If there had been no CS-UCS association worth speaking about, weakening the comparator associations would have made little or no difference.
Of course, the hypothesis can also handle the UCS pre-exposure effect by claiming that a pre-exposed UCS will forge strong links with the comparator stimuli, so that these will be more effective than the CS. (Recall our earlier discussion of the UCS pre-exposure effect as a type of blocking in which the context gets conditioned to the UCS.)
Recently, Blaisdell, Bristol, Gunther, and Miller have claimed a new finding as a success for the comparator approach. This is what they term the pre-exposure overshadowing effect. It arises from experiments that combine aspects of both latent inhibition and overshadowing. Thus, let us take our weakly salient CS (X), and pre-expose it before compounding it with our strong CS (A), according to the following design (actually, rats in Phase 1 who are listed as receiving nothing were actually exposed to a different stimulus):
Group Phase 1 Phase 2
latent inhibition X
alone
X & UCS
overshadowing
(Nothing)
(X+A) & UCS
LI &
OS
X
alone
(X+A) & UCS
acquisition
(Nothing)
X & UCS
In this design, the acquisition group is our control group for how strong a conditioned response we would expect to X alone when there has been no latent inhibition or overshadowing. The first two groups, of course, are there to check on how much responding to X is depressed by one or the other of these procedures. And finally, Group 3 combines them both.
Can you figure out what should happen in Group 3? Would you expect super depression of a response from combining two procedures that depress? Or would you expect the results to be the same as for the latent inhibition only group, on the assumption that X is no longer being paid much attention by the time Phase 2 rolls around? The predictions of the Attentional Models (in the next section below) and the Rescorla-Wagner model seem clear on this. But it turns out that the comparator hypothesis makes a very different prediction. Before talking about why, let's look at the results to see what the pre-exposure overshadowing effect is.
In this experiment, because the UCS was a shock (excitatory-aversive conditioning), we will look at the amount of suppression of drinking when the X is present. If the X has become such a suppressor, then we should find that drinking slows considerably. Our measure will thus be how long it takes our rats to drink a certain amount of liquid (measured by their accumulating 5 sec of observed licking from the drinking tube). That may strike you as an odd thing to measure, but rats that are hesitant to drink or who stop frequently in the middle of drinking will take longer to complete their 5 sec of licking. The results appear in Figure 4.
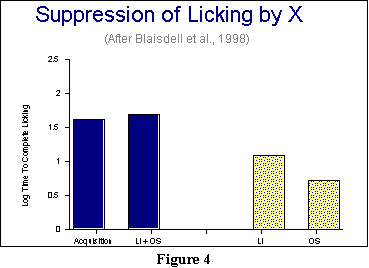 Please note that in Figure
4, a taller bar means more suppression. If you look first at the
results for overshadowing and latent inhibition, graphed on the
right-hand side, you will
see that there is not that much suppression: The effectiveness of our
weak
CS has been reduced compared to when it is presented on its own (the
far
left bar). But the surprise is this: Combining the two procedures of
latent
inhibition and overshadowing results in each canceling out the other!
That
is the finding Blaisdell et al. term pre-exposure overshadowing.
Please note that in Figure
4, a taller bar means more suppression. If you look first at the
results for overshadowing and latent inhibition, graphed on the
right-hand side, you will
see that there is not that much suppression: The effectiveness of our
weak
CS has been reduced compared to when it is presented on its own (the
far
left bar). But the surprise is this: Combining the two procedures of
latent
inhibition and overshadowing results in each canceling out the other!
That
is the finding Blaisdell et al. term pre-exposure overshadowing.
Why does the comparator model predict this? According to Blaisdell et al., X's comparator stimuli in latent inhibition involve the context cues, while X's comparator stimulus in overshadowing involves the other CS, A. Because different comparator cues are activated when X is associated with both latent inhibition and overshadowing, they compete for activation, thus canceling one another out (see the chapter on connectionism for a very similar idea). Blaisdell et al. also speculate on some other mechanisms that may be involved in causing this effect. But regardless of the exact mechanism or mechanisms responsible, they claim that no other currently existing theory can handle this result!
A final point before we go on to the next set of theories: As you might expect, the point at which critical tests of the comparator hypothesis will occur will tend to focus on so-called inhibitory effects. (Not that this is the only possible chink in the theory's armor: Miller and Schachtman do not find that further pairings with the comparator cues depress the conditioned response to the CS, although presenting the comparator cues without the CS may cause the CS-Comparator link to weaken, thus offsetting whatever advantage you get by strengthening the comparator-UCS link.) Thus, it may surprise you to learn that Williams, Overmeir, and LoLordo claim that there really is a component of inhibition in the comparator hypothesis. In an article on the status of inhibition, they pointed out that the comparator model does make the right predictions about the summation and retardation tests, though for very different reasons than are presented by Rescorla. Specifically, if we view the comparison process as taking a sum of the two activations of the UCS, then that sum can obviously be negative (for example, if the sum involves UCSD minus UCSI , and UCSD is smaller ). The retardation test will now work, for example, because of the additional training needed to make that sum larger before the comparison swings the opposite way. A similar consideration may be applied to the summation test. Thus, Williams et al. (1992, p. 281), "contend that Miller and Schachtman (1985) have a well-disguised inhibitory process."
Speaking personally, I
find the claim of a disguised inhibitory process not completely
convincing. Regardless of its accuracy, however, everyone (including
Williams et al.) agrees that the comparator model requires acquisition
just of excitatory
links. If there is something that acts like inhibition, that is an
effect
on performance that occurs through the comparison process, and
not acquisition . Whether such an effect may usefully be termed
inhibitory may be a matter of definition.
We have to add some more detail, however, having to do with how an animal processes a potential signal. The detail is this: An animal's attention is limited, so that it needs to choose what to pay attention to. And consistent with some theories of human attention (see the chapter on attention and categorization ), it will attend stimuli or events that it deems important, ignoring the ones that are not. In the case of multiple predictors for a given UCS, it will normally focus attention onto the best predictor, thus learning to ignore the rest.
And of course, things that capture an animal's attention are more likely to be processed as potential predictors than things that do not.
These are very simple ideas, but they make some powerful predictions, and constitute a very appealing framework. Within this framework, Mackintosh claims that we need to distinguish two processes. The first involves the process of forming an association, due to whatever contiguity happens to be in effect. But things may get associated by chance, so that there is a need to track the relevance of that association. And this is where the second, non-associative process comes in. That process involves evaluating various associations for their signal value, and learning to ignore the associations with poor signal value. Conditioning is thus about predictability. Evaluating contingency or signal value allows us, in Mackintosh's (1975, p. 173) words, to
distinguish between the true cause of the occurrence of a particular reinforcer [the UCS] and other events which are only coincidentally related to that reinforcer.So what does such a theory predict? First, it can handle overshadowing as being due to the more salient CS capturing more of the animal's attention. That is not so different from Rescorla and Wagner. But at the same time, it handles an effect not consistent with the delta rule: the finding that blocking typically results in a bit of excitation on the first trial. By the associative principle, the animal forms an association between the second CS and the UCS. By the non-associative principle, however, it detects that the second CS provides no new information, because it is redundant with the first CS. Hence, the animal is learning to tune out the second CS, resulting in true blocking on later trials.
The true strength of the model, however, lies in handling latent inhibition and learned irrelevance. In their study of latent inhibition, Reiss and Wagner showed that latent inhibition was not true inhibition. They used a clever design that was something like the following:
Group Phase 1 Phase 2 Discrimination Training
1
(Nothing)
light & shock;
(tone + light) & no shock
2
tone alone
light & shock
(tone + light) & no shock
Note that Group 2 is our group with pre-exposure of the CS (the tone), the group that ought to display latent inhibition. In Phase 2, both groups are learning a discrimination, one in which the presence of the tone should become associated with true inhibition. So, if the tone is actually gaining some true inhibition in Phase 1, then Group 2 should have faster learning in Phase 2: Their tone would have been partly inhibited already. But that doesn't happen. Instead, Group 2 learns the discrimination more slowly than Group 1, consistent with the type of retardation we see elsewhere with latent inhibition. Why does this happen in Mackintosh's model? His claim is that the CS is indeed likely noticed or paid attention to when it first appears, but the animal quickly discovers that the CS is associated with no significant events. So, it starts paying less attention to it. Effectively, within the framework of the Rescorla-Wagner model, this would be the equivalent of claiming that the CS's rate parameter decreases with initial exposure (something the Rescorla-Wagner model doesn't allow, of course: Rate parameters are constants that don't change in that model).
What about learned irrelevance? To remind you, Rescorla (among others) found that the truly random control resulted in retarding learning, contrary to the claim than it ought to have no effect whatsoever. Such a result was also reported by Baker and Mackintosh, who added that presenting the CS and UCS at random in an initial phase actually had a bigger retardation effect than either presenting the CS or the UCS alone (eliminating the possibility that learned irrelevance was due just to UCS pre-exposure or to latent inhibition). According to the attentional account, presenting both UCS and CS at random should cause the animal to test effectiveness of the CS as a predictor, resulting in the animal learning to completely ignore the CS due to its inability to predict. When the CS finally does act as a good predictor (because of the nasty trick the experimenter has played on the animal), the animal will take much longer to discover this fact, since the CS is no longer among the active hypotheses the animal is evaluating.
Of course, the model can handle the type of unblocking that Dickinson, Hall, and Mackintosh obtained when they went from two shocks to one (see above and the previous chapter): A surprising event may cause a temporary increase in attention to the surrounding cues, and may interfere with the process of learning to ignore a stimulus. As you will recall, the Rescorla-Wagner model was unable to handle unblocking when there appeared to be a decrease in lambda.
Finally, we may also note that some measure of an animal's attention to a stimulus may be given by the strength and duration of its orienting response to that stimulus. Kaye and Pearce, for example, find that CSs that partially (rather than perfectly) predict a UCS retain their orienting responses, signaling that they continue to be attended. In contrast, non-predicting CSs show habituation of their orienting responses, consistent with the claim that they are no longer being attended. Moreover, Hall and Channell have shown that habituation of a CS's orienting response is associated with reduced learning. When they present a CS in a novel environment, it both (1) displays a stronger orienting response, and (2) exhibits stronger conditioning with a UCS. The notion that an orienting response may be taken as a measure of attention thus is a potentially promising avenue for studying how attention relates to learning (an issue we will revisit in the chapter on attention and categorization).
And unfortunately, the notion that orienting responses tell us about attention also signals some of the problems with the Mackintosh model. Thus, to go back to the Kaye and Pearce study, they found that orienting responses decreased over time when the CS was doing a good job of predicting the UCS. This result is not perfectly consistent with Mackintosh's claims. He had earlier stated that an animal pays increasing attention to a predictor that works, but Kaye and Pearce found the opposite.
Hall and Pearce similarly found that a good CS increasingly lost attentional focus. In one of their experiments, they used the following design:
Group Phase 1 Phase 2
1
CS & weak UCS CS
& strong UCS
2
(Nothing)
CS & strong UCS
In Phase 2, they found that learning proceeded more slowly for Group 1. Their claim, consistent with Kaye and Pearce, was that once a predictor was found, it needed to be attended less and less. (Hall and Pearce developed their own version of an attentional model that acted as a challenge to Mackintosh's model, and that handled some findings better than his.)
What is this mysterious
process by which a predictor need be attended less and less? Perhaps
one of
the most widely accepted contemporary accounts of such a process is to
be
found in the writings of Wagner. In updating the Rescorla-Wagner model
to
handle CS processing results, Wagner started developing a theory of
learning
and automaticity that could handle a wide variety of findings.
Within
the framework of such a theory, very good predictors become capable of
being
responded to in an automatic manner: They immediately trigger
appropriate responses. Automatic processes do not require attentional
resources, so
that as automaticity develops, the need for sustained
attention correspondingly decreases. Thus, learning is based on
attentional
processes, but one type of learning by which automatic processes are
formed
results in freeing attention for other tasks.
One of the major processes of short-term memory, according to the Atkinson-Shiffrin model, was rehearsal . We can think of rehearsal generically as a continual reactivation of an event in working memory. For humans, rehearsal often seems to have an articulatory component to it: the continual repeating to oneself of something one would like to remember. Since animals do not have language, we would certainly not want to define rehearsal in those terms for animals! But in any case, such sustained attention (note the link I am deliberately drawing between attention and rehearsal, since I think the two will prove difficult to distinguish in animals) was believed to be related to the formation of a relatively permanent long-term trace. So, working memory involves a temporary memory system, but rehearsal of information in that system can result in making the memory long-lasting.
One of the phenomena Ebbinghaus had discovered but which was intensely studied at this time (and continues to be today) involves the serial position effect (see Murdock, for example). If we give people a list of 10 to 20 items and then see how well they recall the items, we typically obtain a recency effect and a primacy effect. The primacy effect refers to pretty good memory for the first few items that were on the list, and the recency effect refers to pretty good memory for the last few items. (We will revisit all of this in a lot more detail in the chapter on memory). According to Atkinson and Shiffrin, the primacy effect is due to rehearsal. Before working memory gets too full (indeed, overloaded with lists of these sizes), there is time to rehearse the first several items. But by the time you reach the middle of the list, each item will only get a few rehearsals, since new items are continually coming in and crowding old items out. Thus, the first few items should get the most rehearsals. They took the fact that these were well remembered as evidence that rehearsal was necessary to get them into long-term memory. On the other hand, the last few items were well remembered immediately after people heard the list, but not after a delay (e.g., Craik ). Results like these were taken to mean that the last few items were still available in working memory, so they could be dumped out.
As items become familiar, they appear to require less and less attention (and therefore, less and less involvement of working memory). Familiar items will not be rehearsed as much as unfamiliar items.
These influential ideas found their way to researchers working with animal learning, and those researchers started applying modified versions of these models to their work with animals. Such applications are only justified, of course, to the extent that we can demonstrate separate memory systems and processes such as rehearsal in non-human organisms.
In the late 60s and throughout the 70s, in particular, a number of animal researchers developed procedures and tests that seemed to suggest evidence of multiple memory systems and processes such as rehearsal. One particularly popular procedure with which the existence of working memory in animals was explored was the delayed matching to sample task. This procedure involved exposing an animal to a stimulus (a color or a pattern, for example), and after some delay (during which the stimulus had been removed), checking its memory for that stimulus by requiring it to select that stimulus when presented with a choice between it and a never-before-seen stimulus. (We train the animal to 'select' by having it learn a response to a familiar stimulus. There are actually a variety of procedures here; the one discussed represents a sample application.) Much as Brown and the Petersons had found, researchers working with delayed matching to sample discovered that animals could tolerate some delay (evidence of a memory system), but not a very long delay (evidence that the information in this case did not always make it to long-term memory).
Another procedure that achieved a similar conclusion involved the spatial memory task. This task examined a rat's navigation of an eight-arm radial maze (a central platform from which eight arms extend out in different compass directions; the arms may be baited with food at their ends). Olton and his colleagues developed the task and the apparatus, and were interested in seeing how rats would explore the maze to obtain all the food pellets. They discovered that rats were apparently able to visit the arms in a random order, and generally without revisiting an arm from which they had already obtained the food. Olton argued that this, too, displayed the existence of a short-term spatial memory, since rats would have to remember which arms had been visited in order to avoid those.
Finally, specifically on the topic of rehearsal, a number of studies started looking for primacy and recency effects in serial position-like tasks using animals. They generally were more successful in finding recency (which fits a working memory claim), but primacy effects were occasionally reported. Sands and Wright, for example, exposed monkeys to 'lists' of 10 to 20 pictures, and then later presented some of these along with new pictures, one at a time. The monkeys' task involved indicating which were the old pictures. Primacy and recency effects were seen similar to those obtained with humans. If primacy and recency accurately indicate the existence of multiple memory systems and a rehearsal process (a big if, as you will see in a later chapter), then there was evidence suggesting these characterized at least some higher species of animals. Most people today would certainly distinguish between animal working memory and permanent or long-term memory. The later is now normally referred to in animals as reference memory (Honig ).
There are other principles to this model, but let us briefly work through what these two principles will accomplish. On first being exposed to a UCS and a CS, the animal will start rehearsing them. If the CS and UCS are widely spaced apart, the animal would normally not rehearse them together unless there were something very unusual about one of the stimuli causing extraordinarily sustained rehearsals (a novel taste, for example). Thus, the model incorporates some sensitivity to temporal contiguity: Events that are close together are more likely to be rehearsed together. And this, in turn, means that those events are more likely to be stored in reference memory as connected to one another in a single memory or episode. On repetitions of similar episodes, the connections between events strengthen. Stronger memories in long-term memory due to repetitions ought to be more likely to influence the animal's ongoing behavior.
Thus, presentation of one event will partially activate memories involving it, including the memories in which it was connected with the other event. In contrast, rehearsal of two events separately will result in separate memories or episodes being formed, memories in which the two events are not connected. (Our two events, of course, are the CS and the UCS.) In this case, presentation of one event will not be successful in recruiting memories involving the other. And in this case, we ought to see no evidence of learning that involves an association between them. (That is not the same as saying no evidence of learning! Animals are learning about their environments and building memories, but classical conditioning requires a specific type of associative learning in which CS and UCS are connected, and that type of learning will not ensue.)
Let us now add another principle which we have briefly alluded to in the previous paragraph: Stimuli 'prime' their representations in long-term memory; they activate the memories with which they have been associated. This process of activation is what is normally meant by bringing an object into short-term or working memory. They also prime other events with which they have been connected, so that a CS may prime a UCS. However, primed events are familiar events that will not be rehearsed. Thus, as the animal becomes increasingly exposed to the CS and the UCS, the CS may come to prime the mental representation of the UCS before the actual UCS has been presented. When that happens, physical presence of the UCS will not cause further rehearsals of its mental representation in working memory, since there is already a representation of it present. In short, increasing familiarity of both the CS and the UCS results in the animal ceasing to pay attention to them. It now knows what to expect from them (and in this sense may automate its response to the CS, given a strong contingency). Because these are no longer being rehearsed, no further strengthening can occur in long-term or reference memory. That is why, for example, we obtain the diminishing returns curve: This model claims that such a curve is likely to be due to number of joint rehearsals of the CS and UCS. Large changes at the beginning are due to long or numerous rehearsals of unexpected events, but such rehearsals start to create memories which may be primed on later trials, resulting in reduced rehearsals, resulting in smaller changes.
So far, this model should strike you as easily capable of handling a number of familiar findings: the shape of the acquisition curve; discrimination training (CS- is rehearsed by itself); extinction (same explanation); overshadowing (the more noticeable CS will be attended more, and get more rehearsals); blocking (by the time the second CS is presented, the UCS is no longer being rehearsed very much since it is being primed by the first CS, so joint rehearsals of UCS and CS 2 are out); UCS pre-exposure (same explanation: A by-now-familiar UCS will get very few rehearsals); latent inhibition (this time, the CS is the familiar event that is getting relatively few rehearsals when the UCS is introduced, since the CS is being primed by the contextual cues); weakened conditioning in higher-order conditioning (the first-order CS is becoming familiar, and so getting fewer rehearsals); learned irrelevance (both CS and UCS become familiar making later rehearsals of them unlikely); etc.
However, several of the studies conducted to test this model are particularly appealing because of the perspective they promise on how a concept of rehearsal might alter some of the basic principles or findings obtained to date. The concept of rehearsal, for example, promises to change how we look at belongingness, the extended context of learning, and what happens in backwards conditioning.
We start with belongingness. To remind you, in the learned taste aversions work, Garcia and Koelling found that different CSs paired with different UCSs: a light and a noise with a shock, and a taste with becoming ill. Wagner speculated that such results might be due to radically different amounts of rehearsals for these stimuli. Specifically, maybe external CSs such as lights, noises, and shocks are rehearsed for a much smaller period of time than are internal stimuli such as tastes and sensations of illness. If that is the case, belongingness may really have to do with how long two events are rehearsed. In a test of this idea, Krane and Wagner used either the light-noise CS or the taste CS and paired it with a shock UCS at one of three different delays (5 sec, 30 sec, or 210 sec). They found that the light-noise CS did pair with the shock at the short delays, consistent with Garcia and Koelling's results. There was little evidence of pairing at the 210 sec delay, but that is hardly surprising. On the other hand, while they also verified the Garcia and Koelling finding that the flavor CS and the shock did not pair at the 5 sec delay, these two events did form an association at the longer delays !
The Krane and Wagner study thus disputed the idea that certain stimuli are pre-wired to be connected to others. Instead, Krane and Wagner claimed that the results strongly suggested that any effective stimuli ought to form an association, if the right delay interval is found for them. What makes an interval the right delay? Presumably, the relative amounts of rehearsal. If the taste CS is rehearsed for a relatively long time while the shock UCS is rehearsed for a relatively short time, then the episode that may form in working memory when there is a short delay between the two could involve just the taste. Delaying the shock thus makes it more likely that the episode will include both shock and taste together.
The problem with the above account, of course, is that it tends to explain results after the fact. We would like some other method of verifying how long an event is rehearsed. And that is where the next study comes in. This study by Wagner, Rudy, and Whitlow potentially gives us a tool by which to see how long something is rehearsed. It also strongly suggests that what happens between trials may influence learning (the issue of extended context of learning).
Wagner et al. played off of the notion of a distractor task. Brown and the Petersons had used a distractor task (counting backwards by threes) in their studies of working memory to prevent people from rehearsing, since they wanted to see how long working memory lasted in the absence of rehearsal. Thus, Wagner et al. reasoned that an unfamiliar or surprising episode ought to disrupt whatever rehearsal the animal was engaged in, whereas a familiar or expected episode would not (recall that familiar stimuli don't require much attentional resources). So, they set up a design somewhat like the following using the nictitating membrane paradigm and rabbit subjects:
Group Training Post-Trial Episode
1
light & shock
familiar episode 10 sec later
2
light & shock
unfamiliar episode 10 sec later
In this experiment, note that we are presenting an event 10 seconds after the pairing of the CS and the UCS (which is why this is called a post-trial episode , or PTE). Consistent with Wagner's claim that familiar events ought not to disrupt learning much, Group 1 developed an eye blink to the light with 85% probability. The learning for Group 2 worsened, however: They displayed only a 50% probability of a conditioned response, presumably because the unfamiliar episode disrupted their rehearsals of the light and shock. Accordingly, this study provides some strong confirmation of several of the claims Wagner makes.
But we can push the study even further. Let us take several groups of rabbits, and set up the following design:
Group Training Post-Trial Episode
1
light & shock
unfamiliar episode 3 sec later
2
light & shock
unfamiliar episode 10 sec later
3
light & shock
unfamiliar episode 60 sec later
4
light & shock
unfamiliar episode 300 sec later
The logic behind this experiment is that disruption ought to be greater the closer the PTE comes to the CS and UCS. The shorter the delay in disruption, of course, the less CS and UCS ought to be rehearsed together. Consistent with this claim, there is a steady increase in the probability of a conditioned response to the light as we delay the PTE. Significantly, however, it is evident that performance is worse in the 60 sec group than in the 300 sec group, evidence of some processing still going on after a minute.
Note that a PTE in theory could be used to try to gauge how much rehearsal a given CS or UCS is receiving. For example, we might wish to set up the following experiment:
Group Phase 1 Post-Trial Episode Phase 2
1
light
PTE 3 sec later light & UCS
2
light
PTE 15 sec later light & UCS
3
taste
PTE 3 sec later taste & UCS
4
taste
PTE 15 sec later taste & UCS
If, as Krane and Wagner claim, light is rehearsed for much less time than taste, then we might expect more disruption in the taste groups at long delays, resulting in less latent inhibition. So, using latent inhibition combined with PTEs could serve as one technique to assess claims about which species rehearses which CS for how long. (And a similar procedure involving the UCS pre-exposure effect could inform us about rehearsal times for different UCSs.) Thus, we have a potentially powerful technique that would allow us to make predictions about belongingness and CS-UCS intervals on the basis of knowing before the start of an experiment how long something is likely to be rehearsed in working memory.
Another finding that several people reported had to do with excitatory conditioned responses on the first few trials of backwards conditioning. Wagner and Terry investigated these. Their idea was that the UCS on the first few trials was surprising enough to be rehearsed for a long time, effectively overlapping with the CS rehearsals. But as the UCS quickly lost its surprise factor, rehearsals of it decreased, resulting in no overlap. To test this, they used a backwards conditioning paradigm, but either signaled the shock or its absence. If the shock occurs after its absence has been signaled, that should be surprising enough to cause lengthened rehearsals. And they found in this condition that the shock did associate with the following CS, as opposed to the condition where the shock was not surprising. Thus, the reason backwards versus forwards conditioning operates the way it does will also reflect the relative lengths of CS and UCS rehearsals in this theory.
Finally, we can briefly mention two more studies as illustrative of the work inspired by the rehearsal model. One by Terry examined a type of blocking using the nictitating membrane response. However, Terry (as did Wagner and Terry) used what might be called a pre-trial episode: A UCS presented shortly before the CS and UCS were paired. Schematically, his design was as follows:
UCS -----------> CS -----------> UCS
The UCS was a mild shock, and the conditioned response again involved looking for an eye blink.
The Wagner model can be taken to predict that blocking should occur in this situation, because the first UCS ought to activate its representation in working memory so that the second UCS won't be rehearsed as much, resulting in fewer joint rehearsal of the UCS and CS. As predicted by this model, conditioning was considerably weaker.
Terry also eliminated the possibility that the weaker learning was due to interference from backwards conditioning of the CS with the first UCS. In a follow-up experiment, he ran the same design, but varied whether the first UCS was administered to the same region as the second (the regions involved the areas around the left and right eyes). The idea here was that a UCS to a different region isn't the same UCS, and will be rehearsed rather than primed. On the other hand, if the cause of the weakened learning is backwards conditioning, then such conditioning ought to occur regardless of whether the shock is given to the left or to the right. Supporting the priming interpretation, Terry found stronger conditioned responding when the shocks were in different locations.
A very similar study conducted by Pfautz and Wagner used a CS before the CS-UCS pairing, according to the following design:
Group Pre-Trial Episode
1
same CS 2.5, 5, or 10 sec before CS-UCS pairing
2
different CS 2.5, 5, or 10 sec before CS-UCS pairing
The same logic applies: The same CS ought to prime its representation in working memory so that the second CS won't be rehearsed as much, resulting in slowed learning. In fact, the shorter the delay between the first and the second occurrences of the CS, the worse the learning proved to be. We would also predict that result, since an event repeated at relatively long intervals ought to have had a chance to decay or leave working memory, thus allowing the repetition to trigger the rehearsal process.
In Chapter 2, we learned about the spacing effect. The experiments by Terry and by Pfautz and Wagner ought to suggest to you what Wagner's explanation for this would be.
A stimulus that impinges on the sensory system will cause parts of its representation in long-term memory to become highly active; i.e., to enter the A1 state. Shortly after entering that state, the elements will start to lose activity, and enter the A2 state. They decay much more slowly from the A2 state into complete inactivity after some period of time. Moreover, in this new model, whatever elements are present in the A2 state will influence what the conditioned response looks like (although elements in the A1 state also play a role here). In some circumstances, the A1 and A2 states will be similar, resulting in a conditioned response that resembles the unconditioned response. But in other circumstances, the A1 and A2 states may be quite different, in which case we may obtain a conditioned response that is the opposite of the unconditioned response (so that we will account for findings such as antagonistic or compensatory conditioning: see Obrist et al.). Finally, since the A2 state will normally have elements of both the CS and the UCS, the response will reflect an interaction of these, accounting for the type of finding Holland obtained.
How much of a stimulus's representation becomes active (in terms of how many of its components enter A1) will depend on its intensity or salience . Thus, a strong CS or UCS will have many of its elements in the A1 state. (This will prove important for accounting for the asymptote in learning, since A1 will be where an excitatory association forms.) At the same time, a stimulus may cause other stimuli with which it has been associated to enter the A2 state. Thus, a CS that has previously been paired with a UCS will, on being presented, cause its own representation to enter A1, and the representation of the UCS to enter A2.
So far, this should be moderately familiar, although we are now using a different vocabulary. Thus, you can view the A1 state as similar to rehearsal in the earlier Wagner model, and the A2 state as what happens with priming (i.e., a non-rehearsed representation in working memory that blocks later rehearsal). And since you know that stimuli that are rehearsed together bond together in the earlier model, you should have successfully concluded that stimulus elements that are present in the A1 state will form a connection by which they will tend to excite one another. Note that the specific details of the model allow for CS salience to influence asymptotic levels in addition to influencing rate. Note too the explanation of temporal contiguity effects: With long delays, the CS elements are likely to be in the A2 state when the UCS elements are brought into the A1 state.
Let us add one more point here, since it is one of the strengths of this model: To the extent that elements are in different states, the connection between them weakens. Thus, if a CS is primarily represented in A2 while a UCS is primarily represented in A1, some inhibition ought to develop. And in a return to an idea that is more nearly like Pavlov's , this model allows both inhibitory and facilitatory conditioning to occur simultaneously: At any given point in time, some of the elements of a stimulus are likely to be distributed across both states. So, the CS elements in A1 will strengthen linkage with the UCS elements in A1, but the CS elements in A2 will weaken linkage with the UCS elements in A1 (and vice versa: UCS A2 elements will weaken connections with any CS elements still in A1). This mechanism will now account for the diminishing returns curve: As CS and UCS get paired, CS increasingly comes to prime UCS (i.e., to move UCS elements into A2 while the CS elements are in A1). Thus, inhibition starts building up that cancels out the excitation, resulting in lessened net excitation .
The model can handle a
number of findings (and I leave it to you to figure out why the model
makes the proper predictions about what should happen during
extinction, discrimination, overshadowing, blocking, latent inhibition,
or UCS pre-exposure). However, Wagner and Brandon have extended
it to include affective/emotive conditioning (resulting in AESOP),
since response measures based on emotional conditioning sometimes seem
to yield different results than
response measures based on tracking muscle flexions. Rather than go
into
the details of this later version, however, let me finish the section
by
providing one more experiment as an example of the work inspired by
SOP.
This is a 1998 study by Dwyer, Mackintosh, and Boakes. You will
see
that they argue for an extension of SOP based on their findings; at the
same
time, they will claim that their results simply cannot be accounted for
by
comparator theory. (Sound familiar?!)
The idea they test in their
studies is one suggested by Dickinson and Burke that SOP may
have to be modified to allow for excitatory conditioning when two
events are both in the A2 state. There are some prior findings
that suggest we might want to consider this possibility. I won't go
through them, as we will see more direct evidence from Dwyer et al.
But basically, Wagner assumed that nothing would happen if both events
were in A2. Changing SOP to allow conditioning when both are in
A2 may not be a major modification of the theory, although it certainly
starts to do some damage to the idea that two things need to be
rehearsed together in order to associate. More on that later.
In any case, the procedure Dwyer et al. use will be both elegant in its simplicity and interesting in its implications: Use prior conditioning to create two different associations, then use 'priming' to get the associated events of each into the A2 state. If simultaneous presence in the A2 state is sufficient for forming an excitatory link, then we ought to find that our two missing (and non-presented) stimuli have forger a link.
Since this is a bit abstract so far, here is the general design:
Group Phase 1 Phase 2
Experimental Context 1
&
peppermint
Context 1 & almond
Context 2 & almond & sucrose
Control
Context 1 &
peppermint
Context2 & almond
Context 2 & almond & sucrose
In this design, we will attempt to increase the preference for peppermint in the experimental group by attempting to pair it with a highly desired flavor like sucrose (something that has been done in past studies). But the peppermint and the sucrose will never actually be presented together! Rather, in Phase 2, Context 1 cues ought to cause peppermint to be retrieved into the A2 state, whereas almond taste ought to cause a representation of sucrose to be retrieved into A2. Of course, that ought not to happen in our control group: There is nothing present in Phase 2 that should cause a peppermint taste to be deposited in A2. And consistent with the claim that events form excitatory links if they are in the same state (regardless of whether it is A1 or A2), Dwyer et al. find that rats in the experimental group develop a preference for the peppermint taste. So, two non-present events can associate together, if they are brought to mind by other reminders!
Dwyer at al claim that while it might be possible to modify the Rescorla-Wagner model to handle such results (through use of negative alpha values), the results definitely do not fit in with any version of comparator theory (1998, p. 164):
Although comparator theory can explain the revaluation of a previously established connection, it cannot predict the formation of a novel link. (Emphasis added.)I think it does some damage to SOP, as well, at least in terms of this (to me) really appealing notion of joint rehearsal or activation being responsible for learning. As an alternative, I would be happier considering the possibility that perhaps priming sometimes retrieves part of a representation into the A1 state, and not just the A2 state. How to test these two modifications of SOP then becomes the issue for subsequent research.
You should not think that all is otherwise well for SOP, however. Dwyer et al. also point out some findings that appear to be inconsistent with the theory. In particular, they ask how SOP could handle mediated conditioning. Sensory preconditioning is an example of mediated conditioning. And to remind you, in sensory preconditioning, a CS that has never actually been paired with a UCS comes to form a connection to it. The issue this raises for SOP, of course, is how the association might have formed when only one of these stimuli could have been in the A1 state. Thus, to quote Dwyer et al. (1998, p. 163), such "experiments suggest that both excitatory and inhibitory conditioning can occur to a stimulus in the absence of that stimulus." And in particular, they suggest that a CS in either A1 or A2 might form excitatory links with a UCS in A1, but inhibitory links with a UCS in A2. That type of possibility would seem substantially to violate the spirit of SOP.
So, to summarize, we have seen a number of experiments that claim to be inconsistent with a given model of classical conditioning, but not all such experiments have been inconsistent with the same model! Dwyer et al present data they claim is incompatible with a comparator approach whereas Blaisdell et al. present results they claim are incompatible with anything else. Modifications to the Rescorla-Wagner model are still appearing to handle some of these recent findings.
The field of classical
conditioning theories is alive and well and kicking!
Atkinson, R.C., & Shiffrin, R.M. (1968). Human memory: A proposed system and its control processes. In K.W. Spence & J.T. Spence (Eds.), The psychology of learning and motivation (Vol. 2). NY: Academic.
Baker, A.G., & Mackintosh, N.J. (1976). Learned irrelevance and learned helplessness: Rats learn that stimuli, reinforcers, and responses are uncorrelated. Journal of Experimental Psychology: Animal Behavior Processes, 2, 130-141.
Balaz, M.A., Capra, S., Hartl, P., & Miller, R.R. (1981). Contextual potentiation of acquired behavior after devaluing direct context-US associations. Learning and Motivation, 12, 383-397.
Blaisdell, A.P., Bristol, A.S., Gunther, L.M., & Miller, R.R. (1998). Overshadowing and latent inhibition counteract each other: Support for the comparator hypothesis. Journal of Experimental Psychology: Animal Behavior Processes, 24, 335-351.
Brown, J.A. (1958). Some tests of the decay theory of immediate memory. Quarterly Journal of Experimental Psychology, 10, 12-21.
Colavita, F.B. (1965). Dual function of the US in Classical salivary conditioning. Journal of Comparative and Physiological Psychology, 60, 218-222.
Denniston, J.C., Savastano, H.I, & Miller, R.R. (2001).
The extended comparator hypothesis: Learning by contiguity,
responding by relative strength. In R.R. Mowrer & S.B. Klein
(Eds.), Handbook of contemporary learning theories (pp.
65-117). New Jersey: Erlbaum.
Dickinson, A., & Burke, J. (1996). Within-compound associations mediate the retrospective revaluation of causality judgments. Quarterly Journal of Experimental Psychology. B. Comparative and Physiological Psychology, 49B, 60-80.
Dickinson, A., Hall, G., & Mackintosh, N.J. (1976). Surprise and the attenuation of blocking. Journal of Experimental Psychology: Animal Behavior Processes, 2, 313-322.
Dwyer, D.M., Mackintosh, N.J., & Boakes, R.A. (1998). Simulatneous activation of the representations of absent cues results in the formation of an excitatory association between them. Journal of Experimental Psychology: Animal Behavior Processes, 24, 163-171.
Garcia, J., Ervin, F.R., & Koelling, R.A. (1966). Learning with prolonged delay of reinforcement. Psychonomic Science, 5, 121-122.
Garcia, J., & Koelling, R.A. (1966). Relation of cue to consequence in avoidance learning. Psychonomic Science, 4, 123-124.
Gibbon, J., & Balsam, P.D. (1981). Spreading association in time. In C.M. Locurto, H.S. Terrace, & J. Gibbon (Eds.), Autoshaping and conditioning theory (219-253). CA: Academic.
Gleick, (1992). Genius: The life and science of Richard Feynman. NY: Pantheon.
Grahame, N.J., Barnet, R.C., Gunther, L.M., & Miller, R.R. (1994). Latent inhibition as a performance deficit resulting from CS-context associations. Animal Learning and Behavior, 22, 395-408.
Hall, G., & Channell, S. (1985). Differential effects of contextual change on latent inhibition and on the habituation of an orienting response. Journal of Experimental Psychology: Animal Behavior Processes, 11, 470-481.
Hall, G., & Pearce, J.M. (1982). Change in stimulus associability during conditioning: Implications for theories of acquisition. In M.L. Commons, R.J. Herrnstein, & A.R. Wagner (Eds.), Quantitative analysis of behavior: Vol 3. Acquisition (221-239). MA: Ballinger.
Hasher, L., & Zacks, R. T. (1979). Automatic and effortful processes in memory. Journal of Experimental Psychology: General, 108 , 356-388.
Hasher, L., & Zacks, R. T. (1984). Automatic processing of fundamental information: The case of frequency of occurrence. American Psychologist, 39, 1372-1388.
Hinson, R.E. (1982). Effects of UCS preexposure on excitatory and inhibitory rabbit eyelid conditioning: An associative effect of conditioned contextual stimuli. Journal of Experimental Psychology: Animal Behavior Processes, 8, 49-61.
Hinson, R.E., & Siegel, S. (1980). Trace conditioning as an inhibitory procedure. Animal Learning and Behavior Processes, 8 , 49-61.
Holland, P.C. (1977). Conditioned stimulus as a determinant of the form for the Pvlovian conditioned response. Journal of Experimental Psychology: Animal Behavior Processes, 3, 77-104.
Holland, P.C., & Rescorla, R.A. (1975). The effect of two ways of devaluing the unconditioned stimulus after first- and second-order appetitive conditioning. Journal of Experimental Psychology: Animal Behavior Processes, 1, 355-363.
Honig, W.K. (1978). On the conceptual nature of cognitive terms: An initial essay. In S.H. Hulse, H. Fowler, & W.K. Honig (Eds.), Cognitive processes in animal behavior (1-14). NJ: Erlbaum.
Kalat, J.W., & Rozin, P. (1971). Role of interference in taste-aversion learning. Journal of Comparative and Physiological Psychology, 77, 53-58.
Kamin, L.J. (1965). Temporal and intensity characteristics of the conditioned stimulus. In W.F. Prokasy (Ed.), Classical conditioning: A symposium (118-147). NY: Appleton-Century-Crofts.
Kamin, L.J. (1968). Attention-like processes in classical conditioning. In M.R. Jones (Ed.), Miami symposium on the prediction of behavior: Aversive stimulation (9-32). FL: U. Chicago Press.
Kamin, L.J. (1969). Predictability, surprise, attention, and conditioning. In B.A. Campbell & R.M. Church (Eds.), Punishment. (279-296). FL: U. Chicago Press.
Kaplan, P.S. (1985). Explaining the effects of relative time in trace conditioning: A preliminary test of a comparator hypothesis. Animal Learning and Behavior Processes, 13, 233-238.
Kaye, H., & Pearce, J.M. (1984). The strength of the orienting response during Pavlovian conditioning. Journal of Experimental Psychology: Animal Behavior Processes, 10, 90-106.
Krane, R.V., & Wagner, A.R. (1975). Taste aversion learning with a delayed shock US: Implications for the "generality of the laws of learning." Journal of Comparative and Physiological Psychology, 88 , 882-889.
Kremer, E.F. (1978). The Rescorla-Wagner model: Losses in associative strength in compound conditioned stimuli. Journal of Experimental Psychology: Animal Behavior Processes, 4, 22-36.
Light, J.S., & Gantt, W.H. (1936). Essential part of reflex arc for establishment of conditioned reflex. Formation of conditioned reflex after exclusion of motor peripheral end. Journal of Comparative Psychology, 21, 19-36.
Mackintosh, N.J. (1975). A theory of attention: Variations in the associability of stimuli with reinforcement. Psychological Review, 82, 276-298.
Mackintosh, N.J. (1978). Cognitive or associative theories of conditioning: Implications of an analysis of blocking. In S.H. Hulse, H. Fowler, & W.K. Honig (Eds.), Cognitive processes in animal behavior (155-175). NJ: Erlbaum.
Mackintosh, N.J. (1983). Conditioning and associative learning . Oxford: Clarendon.
Matzel, L.D., Brown, A.M., & Miller, R.R. (1987). Associative effects of US preexposure: Modulation of conditioned responding by an excitatory training context. Journal of Experimental Psychology: Animal Behavior Processes, 13, 65-72.
Matzel, L.D., Schachtman, T.R., & Miller, R.R. (1985). Recovery of an overshadowed association achieved by extinction of the overshadowing stimulus. Learning and Motivation, 16, 398-412.
Matzel, L.D., Schachtman, T.R., & Miller, R.R. (1988). Learned irrelevance exceeds the sum of CS-preexposure and US-preexposure deficits. Journal of Experimental Psychology: Animal Behavior Processes, 14, 311-319.
McAllister, W.R. (1953). Eyelid conditioning as a function of the CS-UCS interval. Journal of Experimental Psychology, 45, 417-422.
Miller, R.R., Barnet, R.C., & Grahame, N.J. (1995). Assessment of the Rescorla-Wagner model. Psychological Bulletin, 117, 363-386.
Miller, R.R., & Matzel, L.D. (1988). The comparator hypothesis: A response rule for the expression of associations. In G.H. Bower (Ed.), The psychology of learning and motivation (Vol. 22: 51-92). CA: Academic.
Miller, R.R., & Schachtman, T.R. (1985). Conditioning context as an associative baseline: Implications for response generation and the nature of conditioned inhibition. In R.R. Miller & N.E. Spear(Eds.), Information processing in animals: Conditioned inhibition (51-88). NJ: Erlbaum.
Murdock, B.B., Jr. (1962). The serial position effect of free recall. Journal of Experimental Psychology, 64, 482-488.
Obrist, P.A., Sutterer, J.R., & Howard, J.L. (1972). Preparatory cardiac changes: A psychobiological approach. In A.H. Black & W.F. Prokasy (Eds.), Classical conditioning II: Current theory and research. NY: Appleton-Century-Crofts.
Olton, D.S. (1978). Characteristics of spatial memory. In S.H.
Hulse, H. Fowler, & W.K. Honig (Eds.), Cognitive processes in
animal
behavior (341-373). NJ: Erlbaum.
Pavlov, I.P. (1927). Conditioned reflexes: An
investigation of the physiological activity of the cerebral
cortext. (English translation by G.V. Anrep available at the Classics in the
History of Psychology web site.)
Papini, M.R., & Bitterman, M.E. (1990). The role of contingency in classical conditioning. Psychological Review, 97, 396-403.
Pearce, J.M., & Hall, G. (1980). A model for Pavlovian conditioning: Variations in the effectiveness of conditioned but not unconditioned stimuli. Psychological Review, 87, 332-352.
Peterson, L.R., & Peterson, M.J. (1959). Short-term retention of individual verbal items. Journal of Experimental Psychology, 58 , 193-198.
Pfautz, P.L., & Wagner, A.R. (1976). Transient variations in responding to Pavlovian conditioned stimuli have implications for the mechanism of "priming." Animal Learning and Behavior, 4, 107-112.
Rescorla, R.A. (1967). Pavlovian conditioning and its proper control procedures. Psychological Review, 74, 71-80.
Rescorla, R.A. (1968). Probability of shock in the presence and absence of CS in fear conditioning. Journal of Comparative and Physiological Psychology, 66, 1-5.
Rescorla, R.A. (1969). Pavlovian conditioned inhibition. Psychological Bulletin, 72, 77-94.
Rescorla, R.A. (1972). Informational variables in Pavlovian conditioning. In G.H. Bower & J.T. Spence (Eds.), The psychology of learning and motivation (1-46). NY: Academic.
Rescorla, R.A. (1978). Some implications of a cognitive perspective on Pavlovian conditioning. In S.H. Hulse, H. Fowler, & W.K. Honig (Eds.), Cognitive processes in animal behavior (15-50). NJ: Erlbaum.
Rescorla, R.A. (1997). Response-inhibition in extinction. Quarterly Journal of Experimental Psychology. B. Comparative and Physiological Psychology, 50B, 238-252.
Rescorla, R.A., & Wagner, A.R. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In A.H. Black & W.F. Prokasy (Eds.), Classical conditioning II: Current theory and research (64-99). NY: Appleton-Century-Crofts.
Reiss, S., & Wagner, A.R. (1972). CS habituation produces a "latent inhibition effect" but no active "conditioned inhibition." Learning and Motivation, 3, 237-245.
Rizley, R.C., & Rescorla, R.A. (1972). Associations in second-order conditioning and sensory preconditioning. Journal of Comparative and Physiological Psychology, 81, 1-11.
Sands, S.F., & Wright, A.A. (1980). Serial probe recognition performance by a rhesus monkey and a human with 10- and 20-item lists. Journal of Experimental Psychology: Animal Behavior Processes, 6, 386-396.
Siegel, S. (1972). Conditioning of insulin-induced glycemia. Journal of Comparative and Physiological Psychology, 78, 233-241.
Schneider, W., & Shiffrin, R.M. (1977). Controlled and automatic human information processing. I. Detection, search, and attention. Psychological Review, 84, 1-66.
Skinner, B. F. (1938). Behavior of organisms. NY: Appleton-Century-Crofts.
Terry, W.S. (1976). The effects of priming US representations in short-term memory in Pavlovian conditioning. Journal of Experimental Psychology: Animal Behavior Processes, 2, 354-370.
Tolman, E.C. (1932). Purposive behavior in animals and men. NY: Appleton-Century.
Van Hamme, L.J., & Wasserman, E.A. (1994). Cue competition in causality judgments: The role of non-presentation of compound stimulus elements. Learning and Motivation,
Wagner, A.R. (1976). Priming in STM: An information proessing mechanism for self-generated or retrieval-generated depression in performance. In T.J. Tighe & R.N. Leaton (Eds.), Habituation: Perspectives from child development, animal behavior, and neurophysiology. NJ: Erlbaum.
Wagner, A.R. (1978). Expectancies and priming in STM. In S.H. Hulse, H. Fowler, & W.K. Honig (Eds.), Cognitive processes in animal behavior (177-209). NJ: Erlbaum.
Wagner, A.R. (1981). S.O.P.: A model of automatic memory processing in animal behavior. In N.E. Spear & R.R. Miller (Eds.), Information processing in animals: Memory mechanisms. NJ: Erlbaum.
Wagner, A.R.,& Brandon, S.E. (1989). Evolution of a structured connectionist model of Pavlovian conditioning (AESOP). In S.B. Klein & R.R. Mowrer (Eds.), Contemporary learning theories: Pavlovian conditioning and the status of traditional learning theory (149-189). NJ: Erlbaum.
Wagner, A.R., Rudy, J.W., & Whitlow, J.W. (1973). Rehearsal in animal conditioning. Journal of Experimental Psychology, 97, 407-426.
Wagner, A.R., & Terry, W.S. (1975). Backward conditioning to a CS followed by an expected vs. a surprising UCS. Animal Learning and Behavior, 3, 370-374.
Wilcoxin, H.C., Dragoin, W.B., & Kral, P.A. (1971). Illness-induced aversions in rat and quail: Relative salience of visual and gustatory cues. Science, 171, 826-828.
Williams, D.A., Overmeir, J.B., & LoLordo, V.M. (1992). A
reevaluation of Rescorla's early dictums about Pavlovian conditioned
inhibition. Psychological Bulletin, 111, 275-290.